Python 学习记录(3)
数据
主要是对Pandas相关的数据帧等做处理和一定的可视化
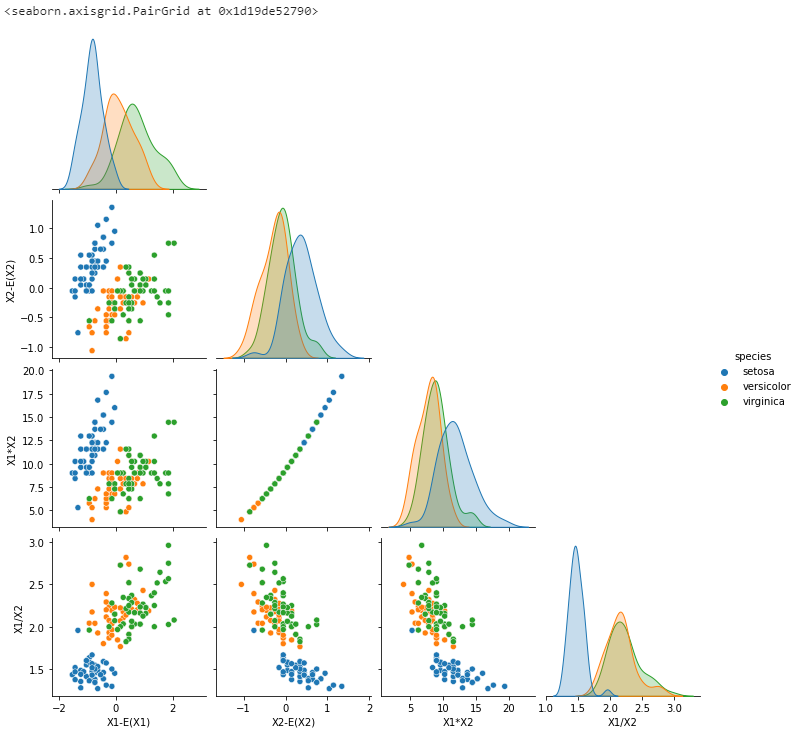
Pandas对数据帧各列的运算
import seaborn as sns
import pandas as pd
#从Seaborn 当中导入鸢尾花数据帧,并处理
iris_df=sns.load_dataset("iris")
X_df=iris_df.copy()
X_df.rename(columns={'sepal_length':'X1',
'sepal_width':'X2'},
inplace=True)
X_df_=X_df[['X1','X2','species']]
#只选择三列
X_df_['X1-E(X1)']=X_df_['X1']-X_df_['X1'].mean()
#新添加一行,用于表示花萼中心化
X_df_['X2-E(X2)']=X_df_['X2']-X_df_['X2'].mean()
#花萼宽度取去均值
X_df_['X1*X2']=X_df_['X2']*X_df_['X2']
X_df_['X1/X2']=X_df_['X1']/X_df_['X2']
#相关相乘与相加
X_df_.drop(['X1','X2'],axis=1,inplace=True)
#删去原先的X1,X2,其中axis=1指明删去的是列,inplace=True说明实在原来的数据帧上操作。
#对相关情况可视化
sns.pairplot(X_df_,corner=True,hue="species")
对其可视化后的结果:
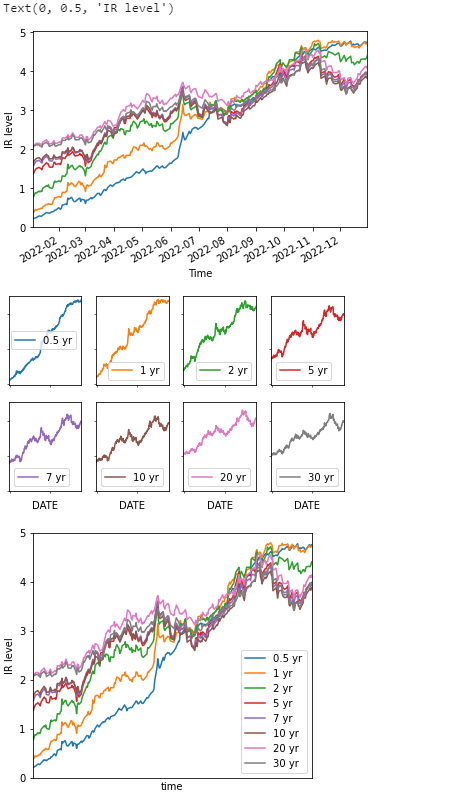
利用Pandas对利率数据的可视化
简单介绍:
- 先利用pandas_datareader从多种数据源中获得金融和经济数据。
- 之后利用python当中的可视化工具进行可视化。
- 最后对图像进行一定的美化。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pandas_datareader as pdr
#如果没有pandas_datareader库/或出现报错
#先将pandas_datareader库下载,pip install pandas_datareader
import seaborn as sns
#----导入数据--start-----
df=pdr.data.DataReader(['DGS6MO','DGS1',
'DGS2','DGS5',
'DGS7','DGS10',
'DGS20','DGS30'],
data_source='fred',
start='01-01-2022',
end='12-31-2022')
df=df.dropna()
#修改数据帧列标签,dropna()方法删除数据帧中缺失值NaN.
df=df.rename(columns={'DGS6MO':'0.5 yr',
'DGS1':'1 yr',
'DGS2':'2 yr',
'DGS5':'5 yr',
'DGS7':'7 yr',
'DGS10':'10 yr',
'DGS20':'20 yr',
'DGS30':'30 yr'})
#对相应对象进行改名
#----end-----
#------简单画图-----
df.plot(xlabel='Time',ylabel='IR level',
legend=False,
xlim=(df.index.min(),df.index.max()))
plt.savefig("利率走势图.svg")
df.plot(subplots=True,layout=(2,4),
sharex=True,sharey=True,
xticks=[],yticks=[],
xlim=(df.index.min(),df.index.max()))
plt.savefig("利率走势图,子图.svg")
#savefig()方法将图片以 SVG 格式进行保存
#----美化线图----
#创建一个图像对象和一个轴对象
fig,ax=plt.subplots(figsize=(5,5))
#fig是一个图形对象,代表整个图形窗口
#ax是一个轴对象,代表图形窗口的子图或者坐标系
df.plot(ax=ax,xlabel="time",legend=True)
#这里ax=ax指定了具体对象
ax.set_xlim((df.index.min(),df.index.max()))
ax.set_ylim((0,5))
ax.set_xticks([])
ax.set_xlabel('time')
ax.set_ylabel('IR level')
结果:
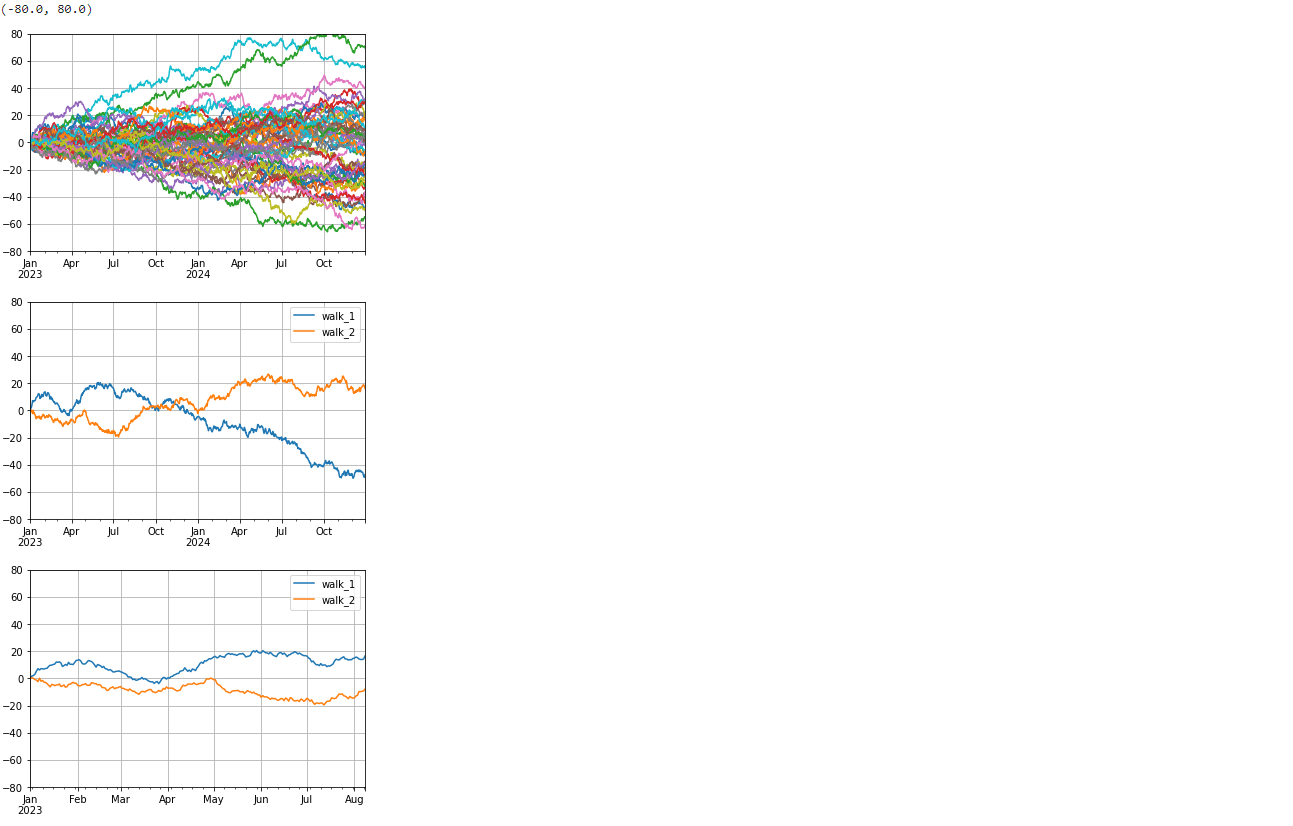
时间序列数据帧索引与切片
简单介绍:
- 蒙特卡罗模拟:蒙特卡罗模拟是通过随机抽样的方法进行数值计算的一种技术.
- 广泛用于金融,物理,工程等领域,解决复杂的概率,统计和优化问题
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
date_range=pd.date_range(start='2023-01-01',
periods=365*2,freq='D')
#创建日期范围,使用date_range()方法
df=pd.DataFrame(index=date_range)
#创建一个空的DataFrame,用于存储随机行走数据,同时将行标签设置成天
num_path=50
np.random.seed(0)
#50个随机数,同时设置随机种子保证结果可重复
for i in range(num_path):
#满足正态分布随机数
step_idx=np.random.normal(loc=0.0,scale=1.0,
size=len(date_range)-1)
#其中有【(365*2)-2】个数据,因将0作为最开始数据
step_idx=np.append(0,step_idx)
walk_idx=step_idx.cumsum()
#将每天走的情况记录且累加放在相应的列下面,其中列下面放的是一堆
#数据非单值,因cumsum()方法计算累加,代表行走随时间变化
df[f'walk_{i+1}']=walk_idx
#------画出三幅图-----
df.plot(legend=False)
plt.grid(True)
plt.ylim(-80,80)
df[['walk_1','walk_2']].plot(legend=True)
plt.grid(True)
plt.ylim(-80,80)
df.loc['2023-01-01':'2023-08-08',
['walk_1','walk_2']].plot(legend=True)
plt.grid(True)
plt.ylim(-80,80)
代码输出情况: