Redis持久化机制(面试考点)与位图API
一,Redis持久化机制详细博客笔记
1. Redis持久化机制概述
Redis是一个基于内存的高性能键值对数据库,其所有数据都存储在内存中。为了确保数据的安全性,防止服务器崩溃导致数据丢失,Redis提供了持久化机制,将内存中的数据保存到磁盘上。Redis支持两种持久化方式:RDB(快照持久化)和AOF(追加文件持久化)。
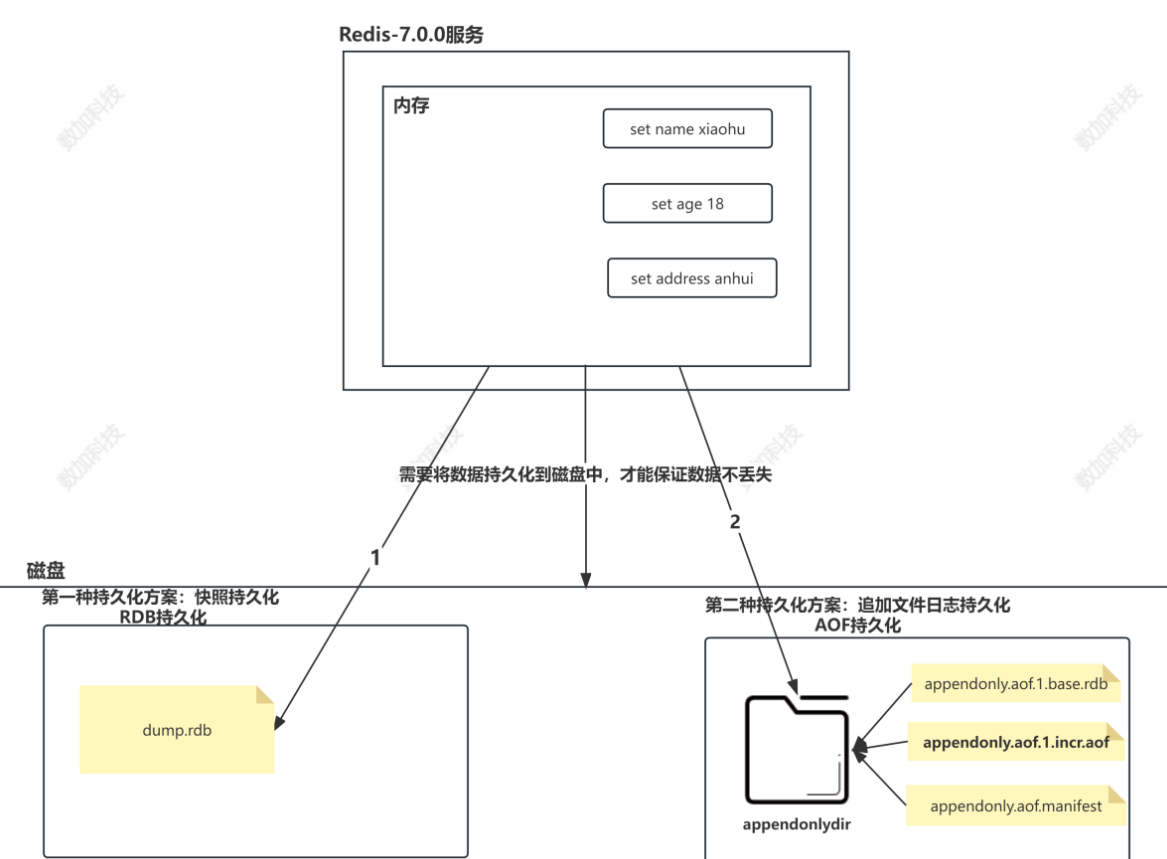
2. RDB持久化(快照)
2.1 RDB特点
- RDB持久化会生成数据集的时间点快照,并将该快照保存到磁盘上的
.rdb文件中。 - 这种方式是Redis默认的持久化方式。
- RDB文件是Redis数据的二进制表示,通过Redis服务器启动时加载
.rdb文件来恢复数据。
2.2 RDB快照生成方式
2.2.1 客户端方式
-
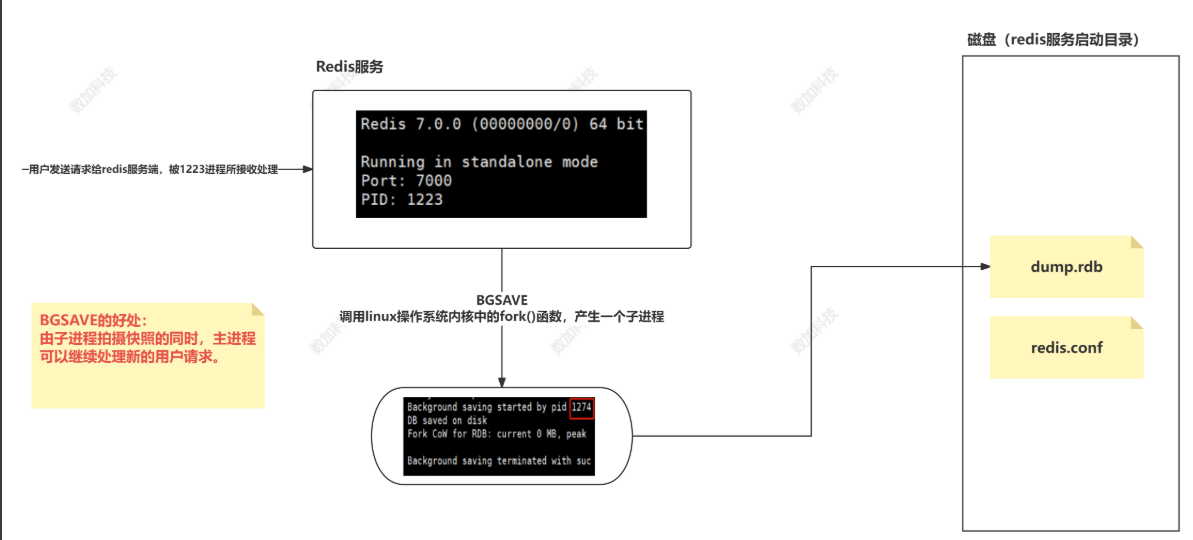
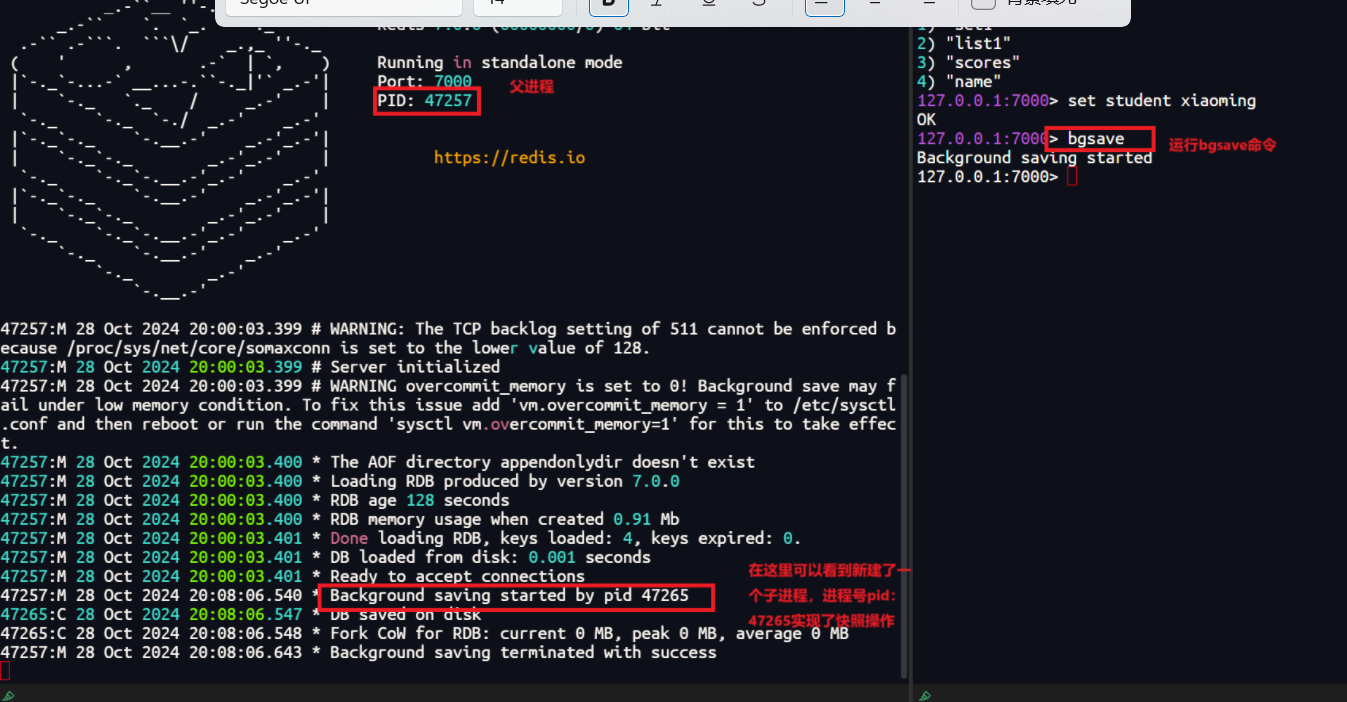
BGSAVE命令:客户端可以发送
BGSAVE命令给Redis服务器,服务器会fork一个子进程来执行快照操作,而父进程继续处理客户端命令。这种方式不会阻塞主线程,因此对服务器性能影响较小。
-
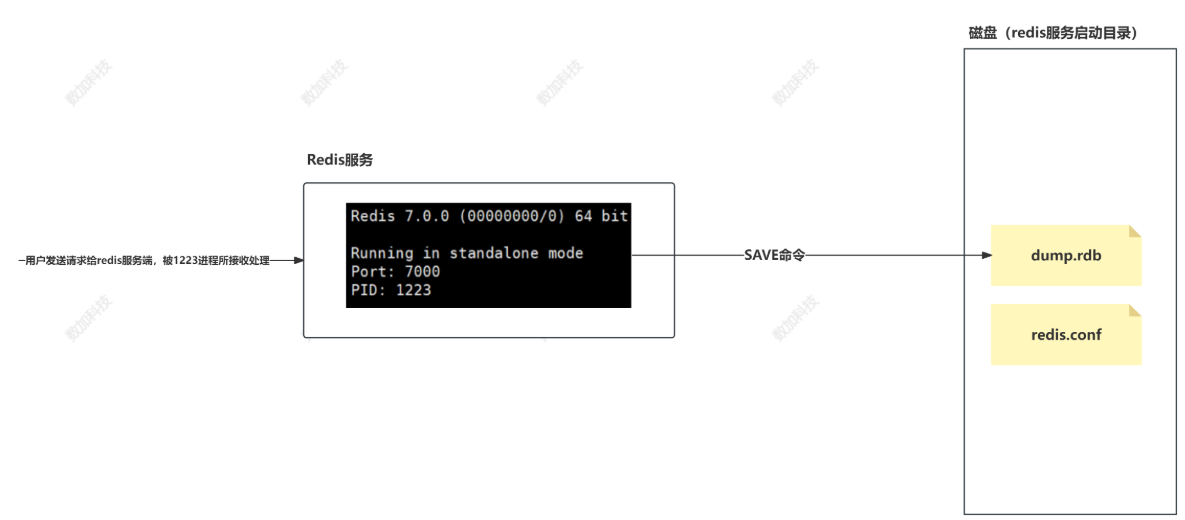
SAVE命令:客户端可以发送
SAVE命令,这会导致Redis服务器阻塞,直到快照操作完成。由于SAVE命令会导致服务器在快照过程中无法处理请求,因此不推荐在生产环境中使用。
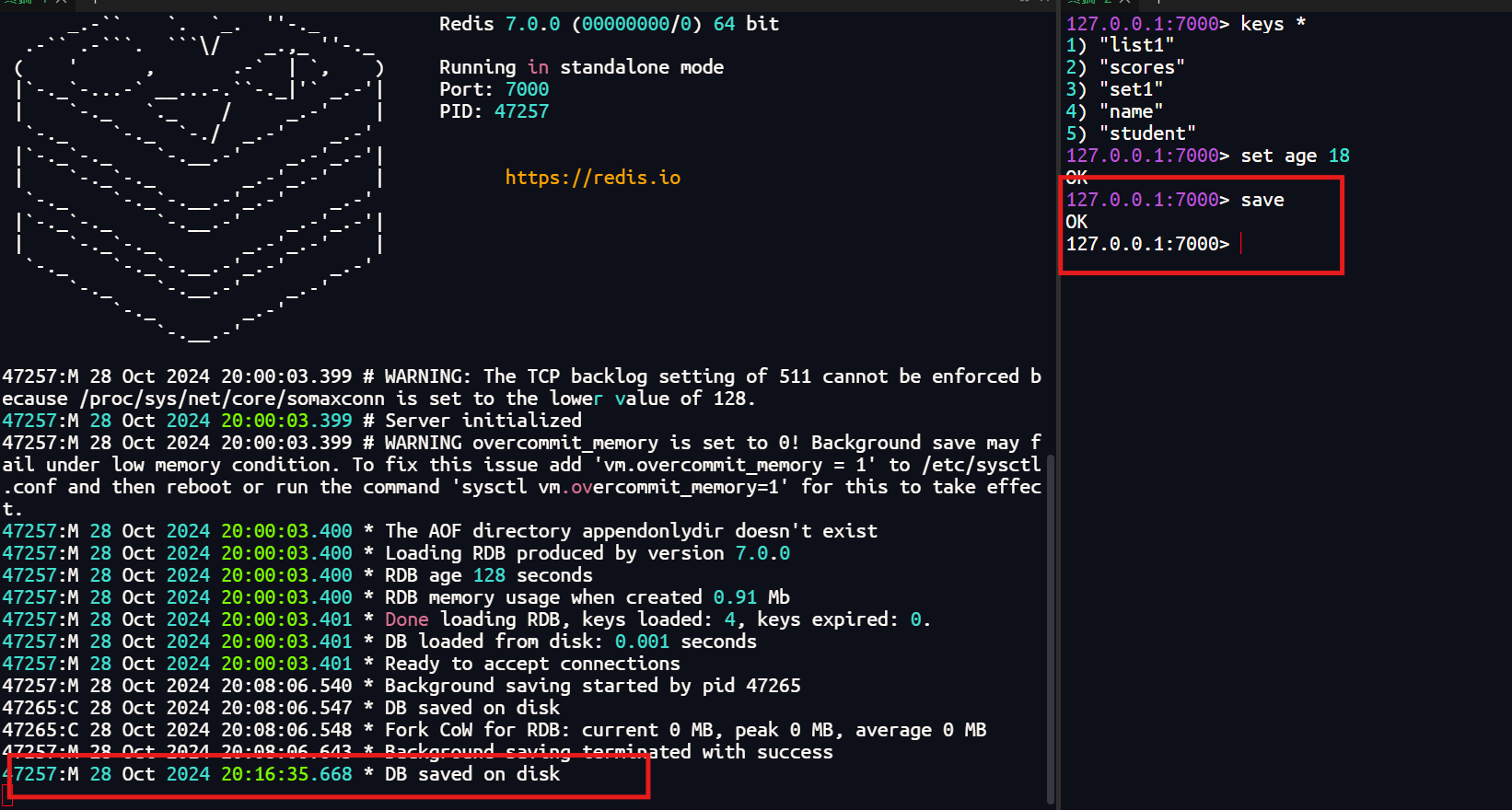
2.2.2 服务器配置自动触发
- 在Redis配置文件
redis.conf中,可以通过设置save选项来自动触发快照。例如,save 900 1表示如果900秒内至少有1个key被修改,则自动执行BGSAVE命令。 - 可以设置多个
save选项,当任意一个条件满足时,都会触发快照。
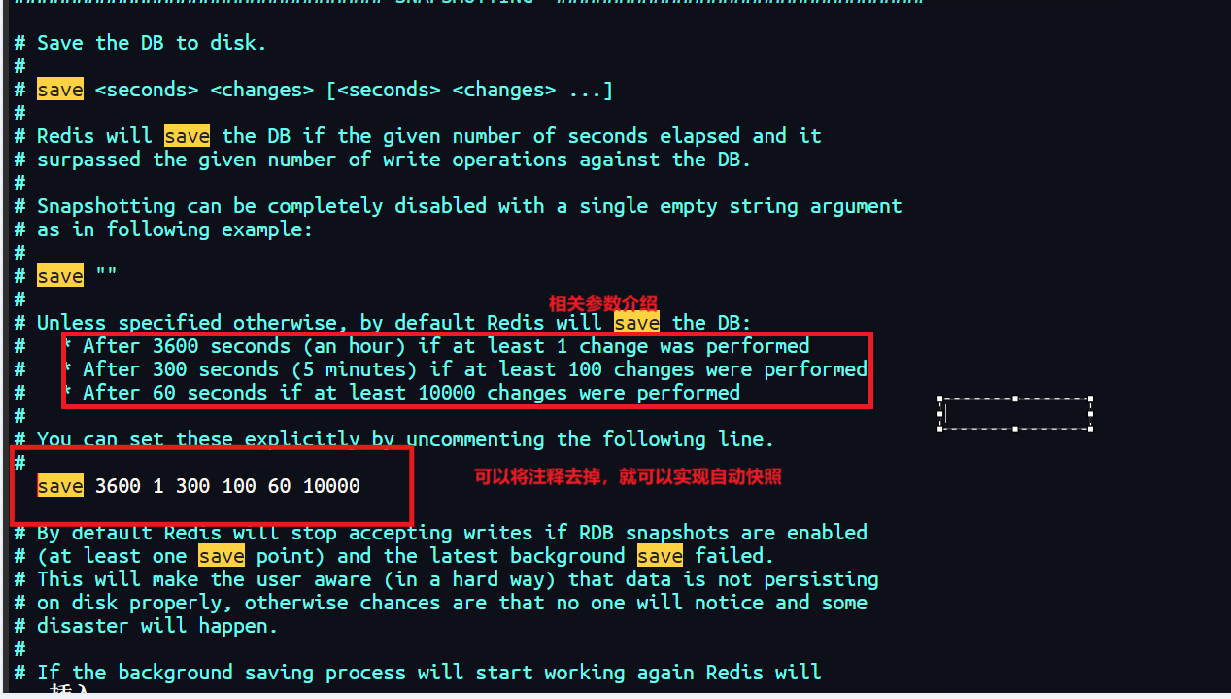
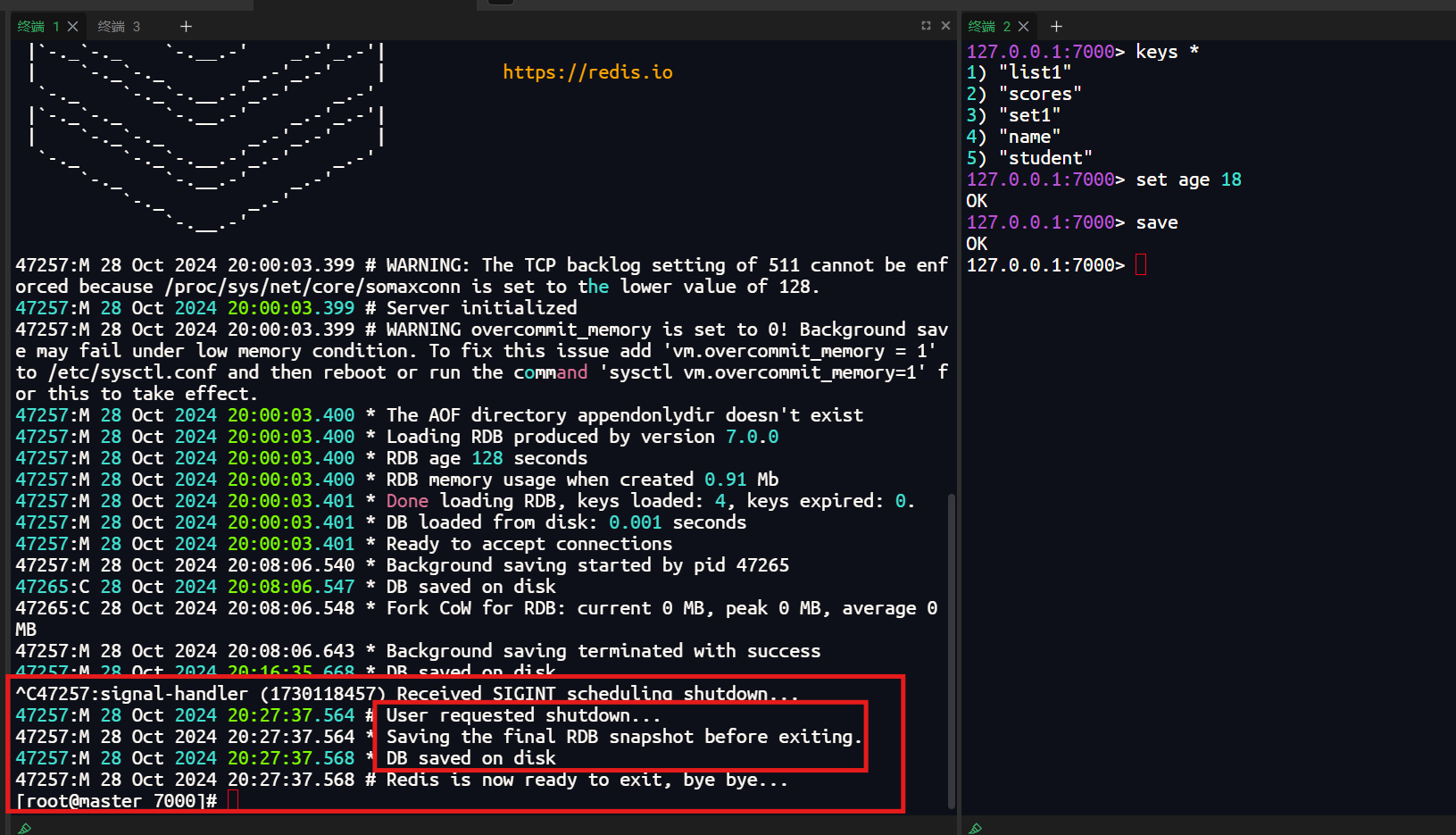
2.2.3 关闭服务器时触发
- 当Redis服务器接收到
shutdown命令时,如果配置了RDB持久化,服务器会执行一次SAVE命令,确保数据的完整性。
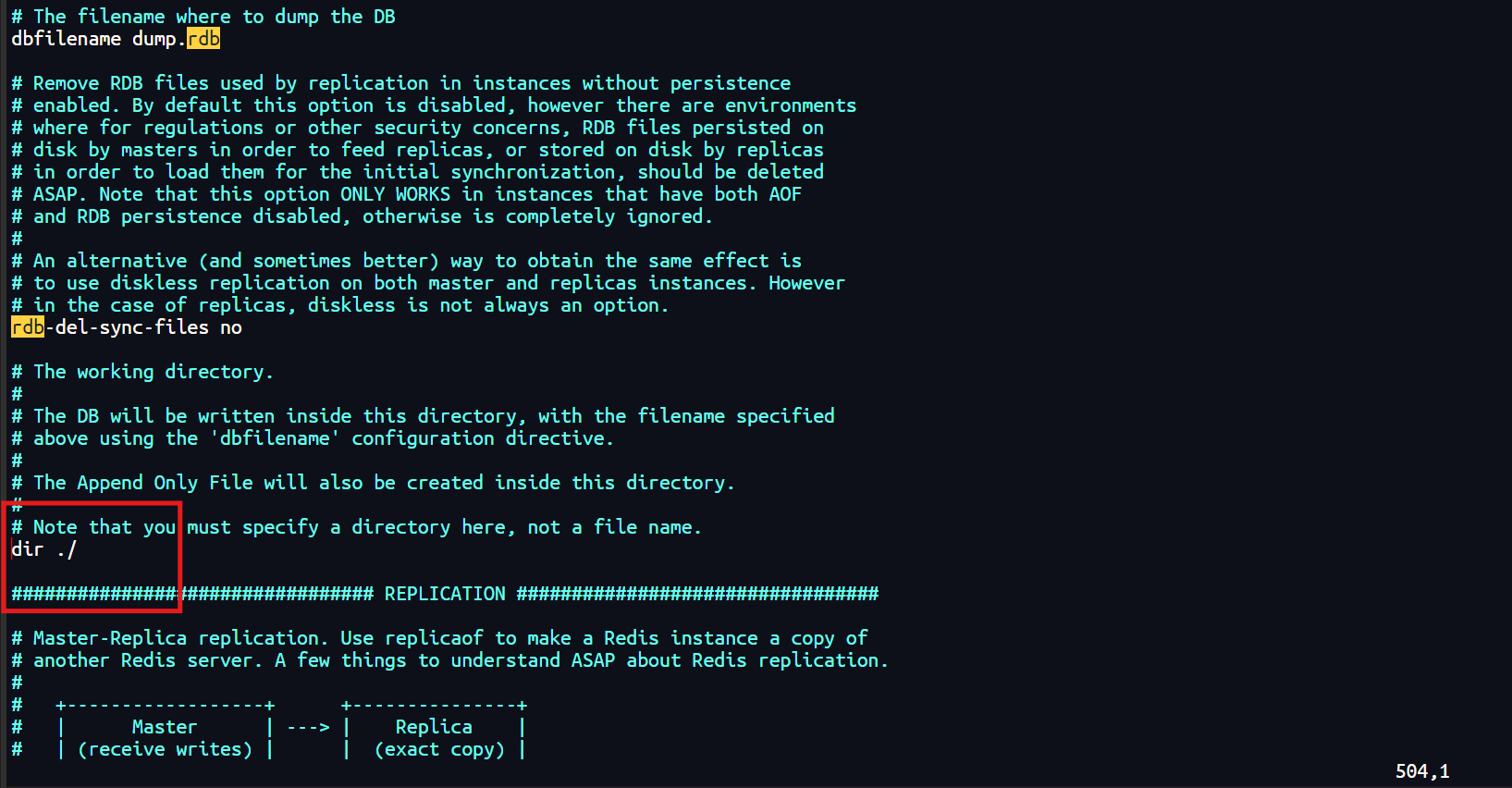
2.3 RDB配置生成快照名称和位置
-
在
redis.conf中,可以通过dbfilename和dir配置项来指定快照文件的名称和存储位置。 -
dbfilename指定快照文件的名称,默认为dump.rdb。
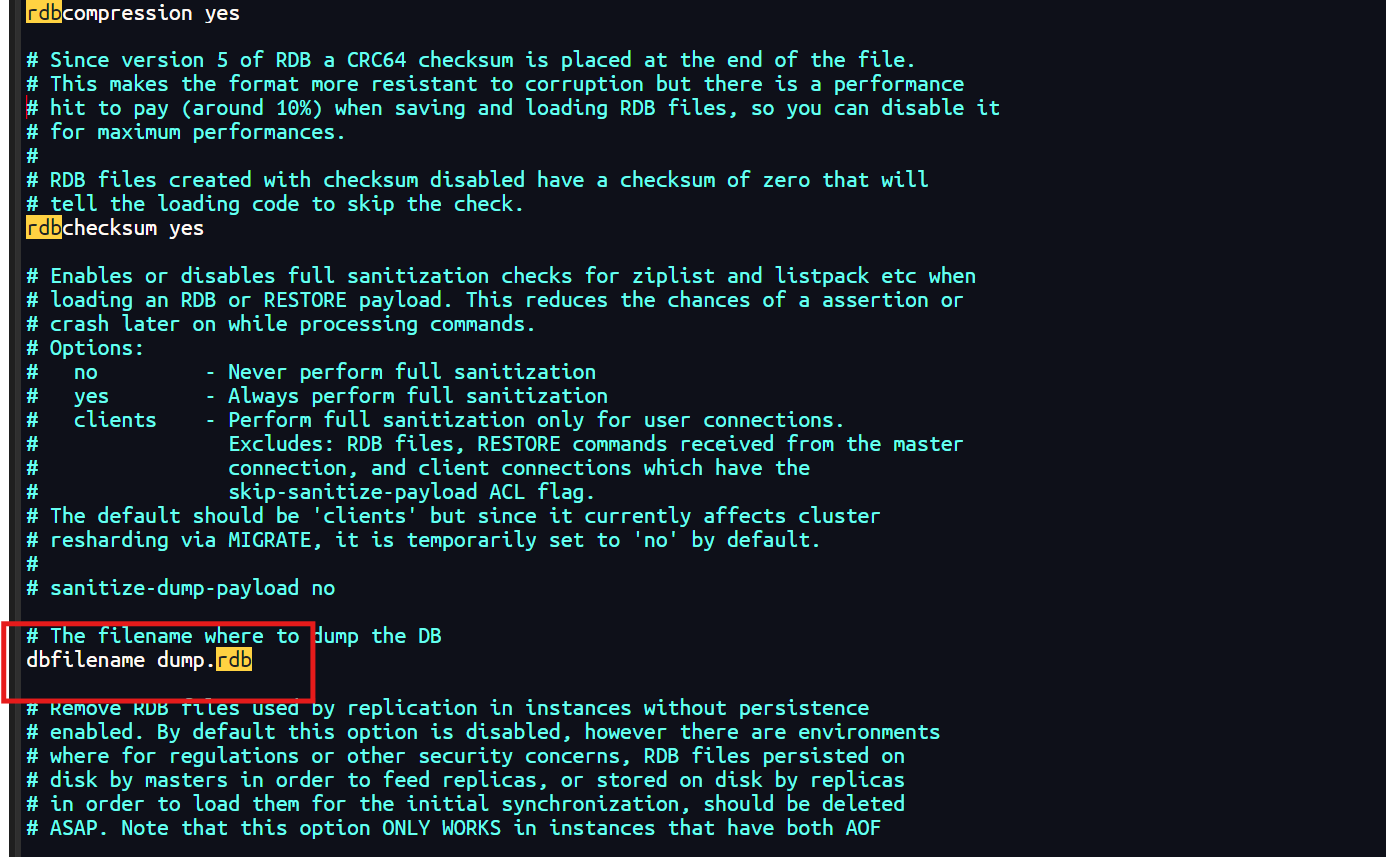
-
dir指定快照文件的存储目录,默认为Redis服务器的工作目录。
2.4 RDB持久化优缺点
- 优点:RDB文件体积小,恢复速度快;适用于灾难恢复。
- 缺点:在故障发生时可能会丢失最近的数据(取决于快照频率)。
3. AOF持久化(只追加日志文件)
3.1 AOF特点
- AOF持久化记录每次写操作命令,并追加到日志文件中。
- 通过执行AOF文件中的命令来恢复数据集。
- AOF文件以纯文本形式存储,易于理解。
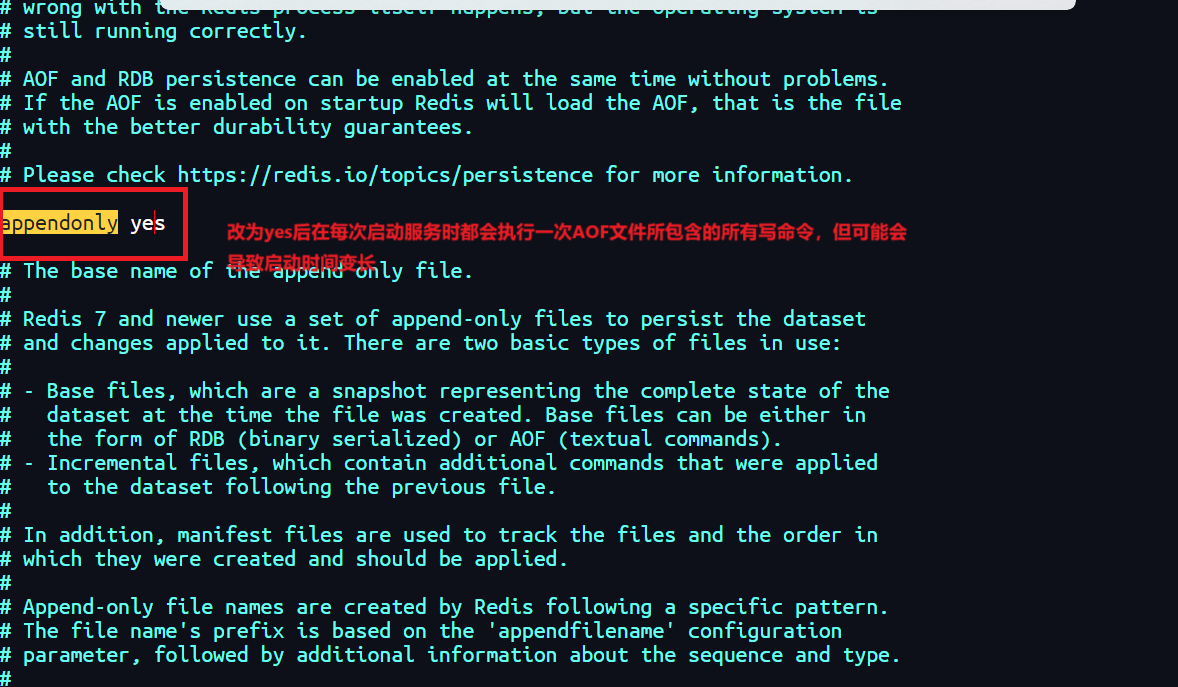
3.2 开启AOF持久化
-
在
redis.conf中设置appendonly yes来开启AOF持久化。
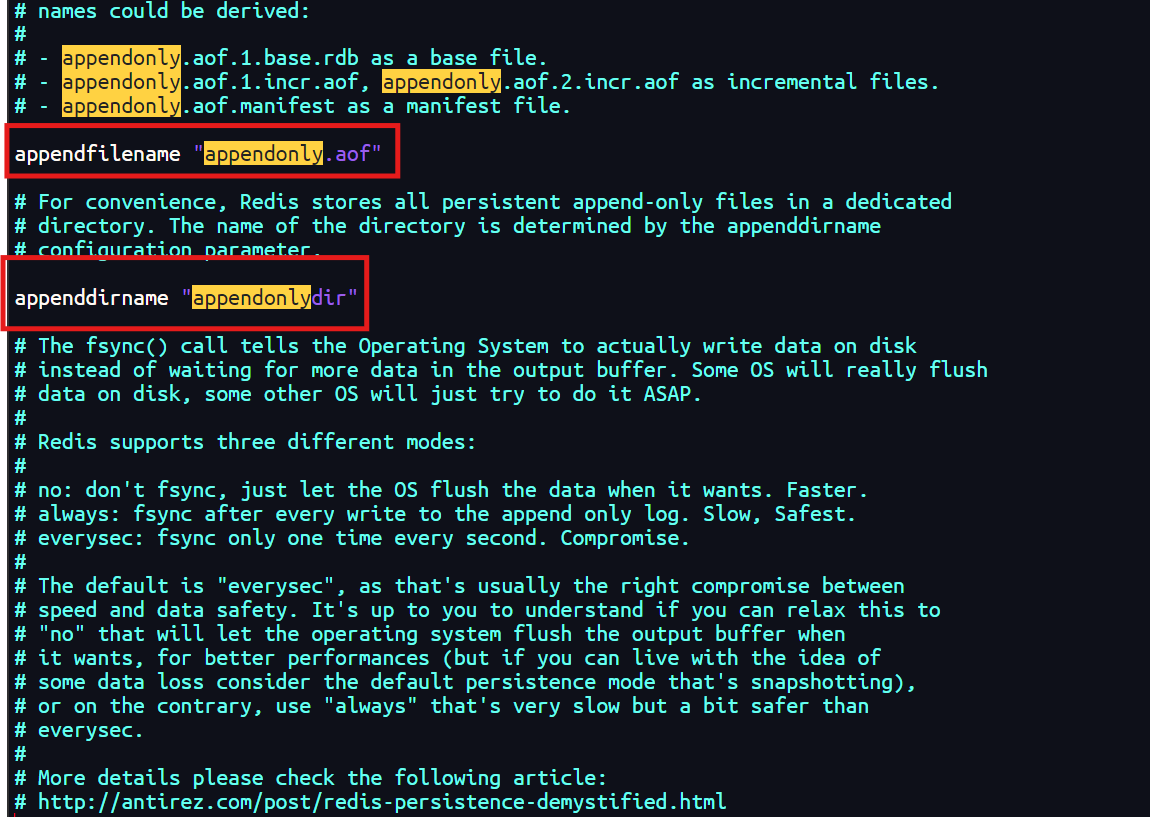
-
通过
appendfilename指定AOF文件的名称,默认为appendonly.aof。
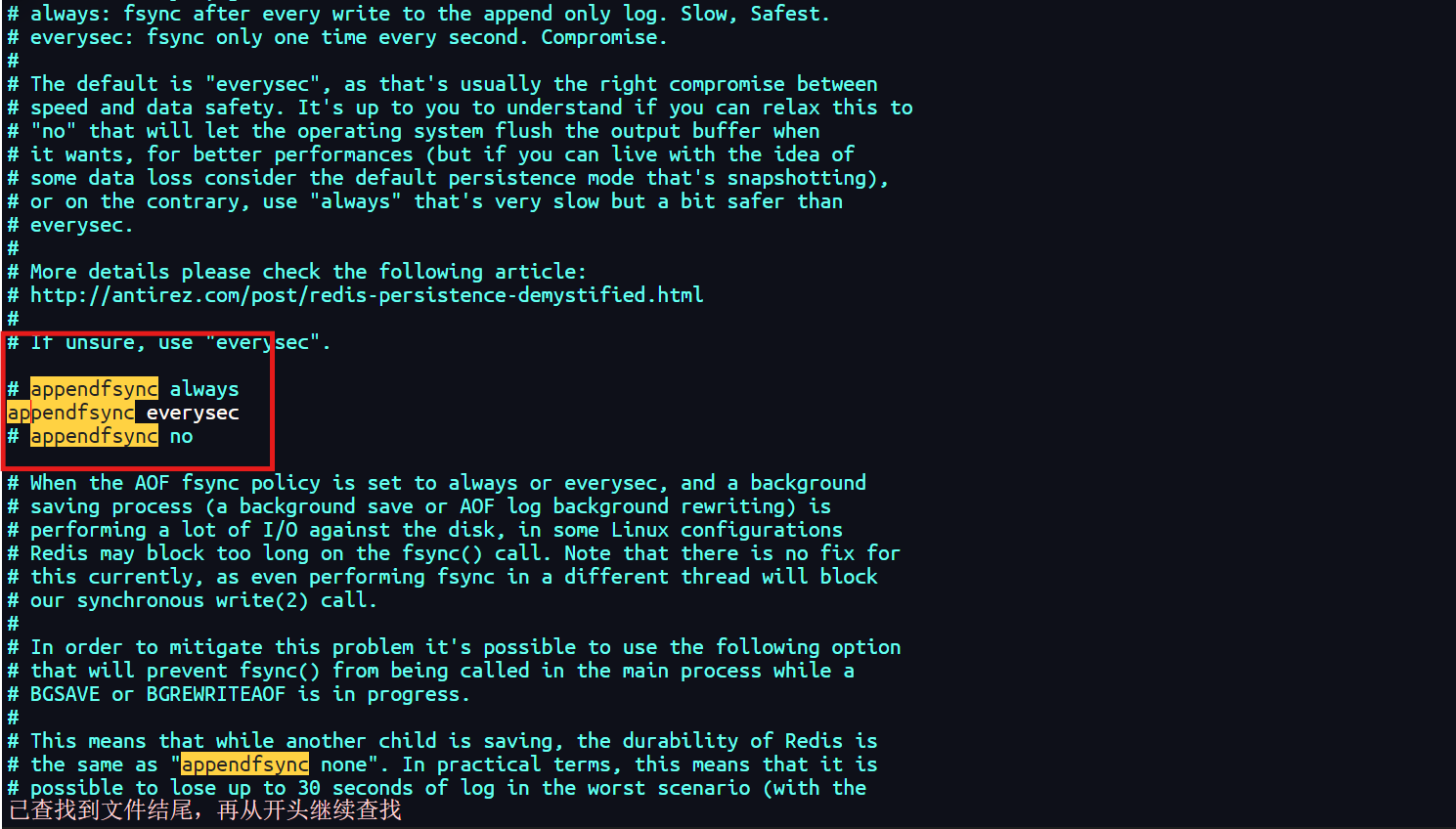
3.3 AOF日志追加频率
1. always【谨慎使用】
- 说明:每个Redis写命令都要同步写入硬盘,这会严重降低Redis的速度。
- 解释:使用
always选项意味着每个写命令都会被立即写入硬盘,从而将系统崩溃时数据丢失的风险降到最低。然而,这种同步策略需要对硬盘进行大量的写入操作,因此Redis处理命令的速度会受到硬盘性能的限制。 - 注意:对于转盘式硬盘,这种频率下大约只能处理200个命令/秒;对于固态硬盘(SSD),可以处理几百万个命令/秒。
- 警告:对于使用SSD的用户,应谨慎使用
always选项,因为这种模式下不断写入少量数据可能会引发严重的“写入放大”问题,导致固态硬盘的寿命从几年降低到几个月。
2. everysec【推荐默认】
- 说明:每秒执行一次同步,显式地将多个写命令同步到磁盘。
- 解释:为了平衡数据安全和写入性能,用户可以考虑使用
everysec选项,让Redis以每秒一次的频率对AOF文件进行同步。在这种设置下,Redis的性能与不使用任何持久化特性时的性能相差无几,同时可以保证即使系统崩溃,用户最多只会丢失一秒内产生的数据。
3. no【不推荐】
- 说明:由操作系统决定何时同步。
- 解释:使用
no选项意味着完全由操作系统决定何时同步AOF日志文件,这个选项不会对Redis性能带来影响。但是,系统崩溃时可能会丢失不定数量的数据,甚至全部数据。此外,如果用户的硬盘处理写入操作不够快,当缓冲区被等待写入硬盘的数据填满时,Redis会处于阻塞状态,导致处理命令请求的速度变慢。
3.4 AOF文件的重写(面试重点)
3.4.1 AOF带来的问题
- AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件Redis提供了AOF重写(ReWriter)机制。
3.4.2 AOF重写触发方式
- 客户端方式:执行
BGREWRITEAOF命令,不会阻塞Redis服务。 - 服务器配置方式:在
redis.conf中设置auto-aof-rewrite-percentage和auto-aof-rewrite-min-size自动触发重写。例如,设置auto-aof-rewrite-percentage 100和auto-aof-rewrite-min-size 64mb,当AOF文件大小超过64MB且比上一次重写后体积增长超过100%时,自动触发重写。
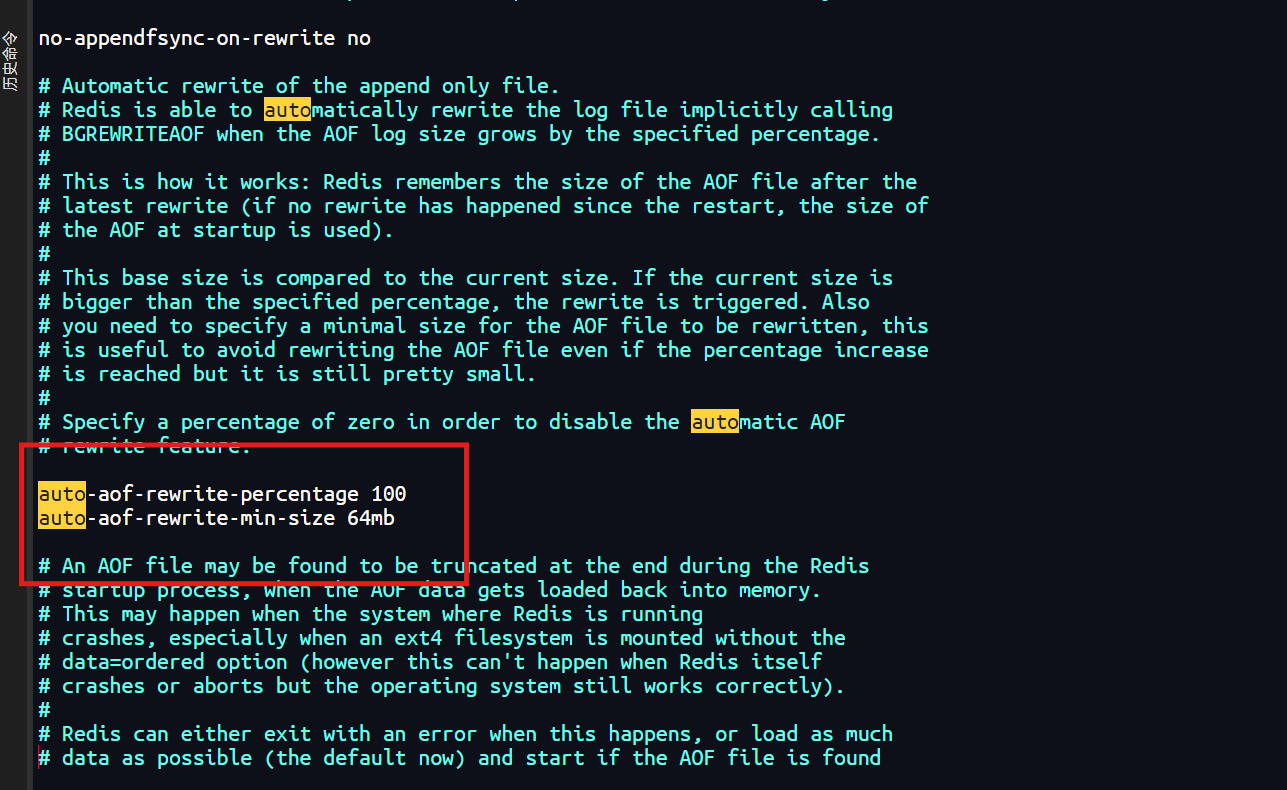
Redis 7.0.0 多部分AOF机制
从Redis 7.0.0版本开始,引入了多部分AOF机制,该机制将原来的单个AOF文件拆分为两个部分:基础文件和增量文件。
- 基础文件:最多只有一个,表示重写AOF时存在的数据的初始状态(可以是RDB或AOF格式的快照)。
- 增量文件:可能不止一个,包含自创建最后一个基础AOF文件以来的增量更改。
- 所有这些文件都存放在一个单独的目录中,并由一个清单文件进行跟踪。
AOF重写调度与执行
在Redis 7.0.0及以后的版本中,AOF重写的调度和执行过程如下:
- 父进程操作:Redis父进程会打开一个新的增量AOF文件继续写入,以保证服务不中断。
- 子进程操作:子进程执行重写逻辑,生成新的基础AOF文件。
- 临时清单文件:Redis使用一个临时清单文件来跟踪新生成的基础文件和增量文件。
- 原子替换操作:当新文件准备好后,Redis执行原子替换操作,使临时清单文件生效,完成重写的AOF文件替换旧文件的过程。
AOF重写限制机制
为了避免AOF重写失败和重试时创建大量增量文件的问题,Redis引入了AOF重写限制机制。该机制确保失败的AOF重写会以越来越慢的速度重试,从而减少对系统资源的冲击。
图解
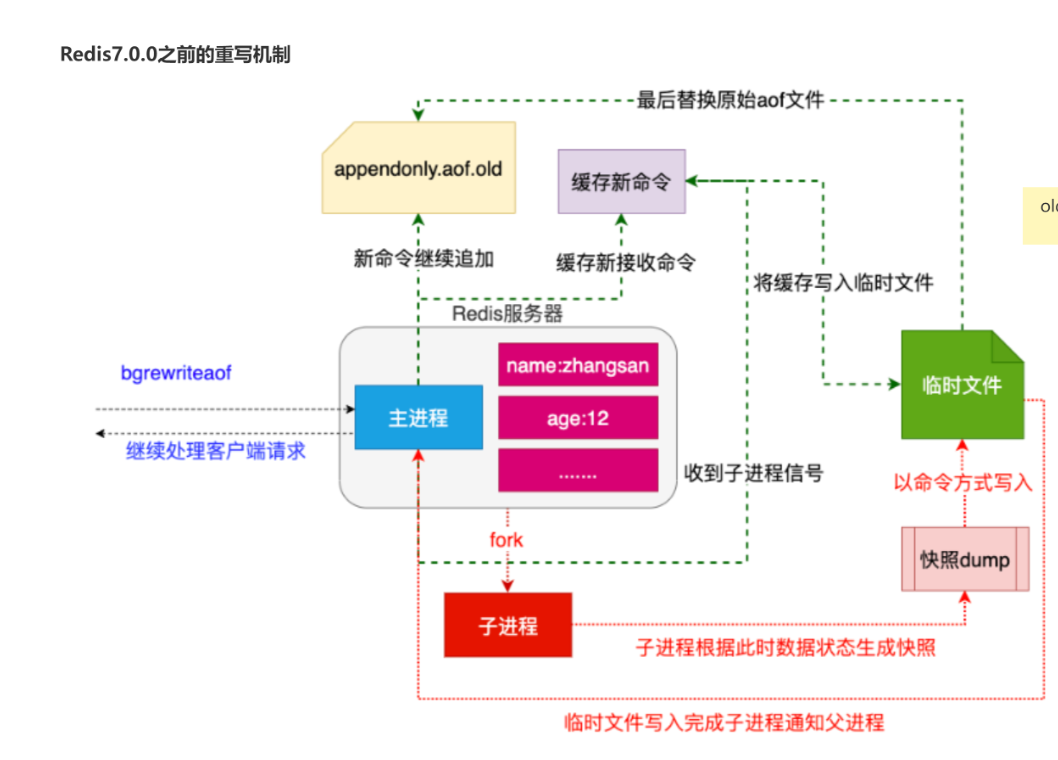
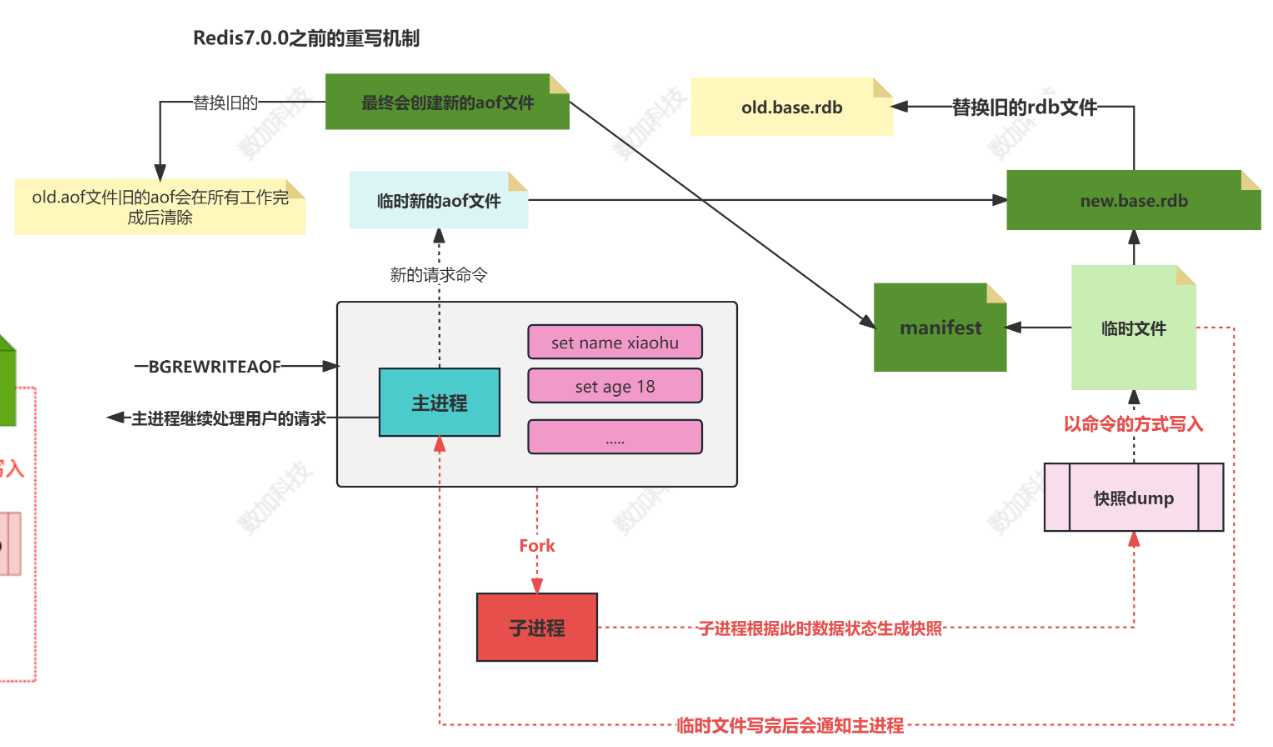
AOF重写流程
AOF重写的详细流程包括以下步骤:
- Fork子进程:Redis调用fork产生一个子进程,父子两个进程开始并行工作。
- 子进程重写:子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令。
- 父进程缓存:父进程继续处理客户端请求,将写命令写入到原来的AOF文件中,同时缓存收到的写命令,以保证子进程重写失败时数据不会丢失。
- 子进程通知:子进程完成快照内容写入后,发信号通知父进程。
- 父进程写入缓存:父进程将缓存的写命令也写入到临时文件中。
- 替换旧文件:父进程使用临时文件替换旧的AOF文件,并重命名,之后收到的写命令开始往新的AOF文件中追加。
注意事项
重写AOF文件的操作并没有读取旧的AOF文件,而是将整个内存中的数据库内容用命令的方式重写一个新的AOF文件,替换原有的文件,这一点和快照有点类似。
4.Redis持久化机制总结
1. Redis持久化方案种类
Redis提供了两种主要的持久化方案:
- RDB持久化:通过创建内存数据的快照来实现持久化。
- AOF持久化:通过记录每条写操作命令来实现持久化。
2. Redis默认持久化方案
Redis默认使用的持久化方案是RDB持久化。
3. 触发RDB持久化的方式及其区别
RDB持久化可以通过以下四种方式触发:
- BGSAVE命令:客户端发送
BGSAVE命令给Redis服务器,服务器fork一个子进程来创建快照,父进程继续处理命令,不影响服务器性能。 - SAVE命令:客户端发送
SAVE命令,Redis服务器会阻塞直到快照完成,不响应其他命令。 - 默认触发策略:在配置文件中设置
save选项,如save 900 1表示900秒内至少有1个key被修改,则自动执行BGSAVE。 - shutdown命令:执行
shutdown命令时,如果配置了RDB持久化,Redis会执行一次SAVE命令。
4. AOF持久化与RDB持久化的优缺点
-
RDB持久化:
- 优点:恢复速度快,只保留一个数据文件,节省存储空间。
- 缺点:可能会丢失最近的数据(最后一次快照后的数据)。
-
AOF持久化:
- 优点:数据安全性高,可以设置为每秒同步,最多丢失一秒的数据。
- 缺点:文件体积大,恢复速度慢,对磁盘I/O要求高。
5. Redis 7.0之后的持久化方案:RDB+AOF
Redis 7.0引入了RDB和AOF的组合持久化方案,旨在结合两者的优点:
- 基础文件:存储RDB快照。
- 增量文件:存储自上次快照以来的AOF命令。
这种方案通过分层次的文件管理,提高了数据恢复的效率和灵活性。
6. Redis 7.0之前与之后的AOF重写机制
-
Redis 7.0之前:
- 重写AOF文件时,子进程读取旧的AOF文件,并根据当前内存状态生成一个新的AOF文件。
- 父进程继续接收写命令,并缓存起来,以便在重写失败时恢复。
- 重写完成后,原子替换旧的AOF文件。
-
Redis 7.0之后:
- 引入多部分AOF机制,包括基础文件和多个增量文件。
- 父进程在重写期间继续写入一个新的增量文件。
- 子进程生成新的基础文件,使用临时清单文件跟踪新文件。
- 重写完成后,通过原子替换操作更新清单文件,完成AOF文件的更新。
这种新的重写机制提高了重写的效率,并减少了因重写失败导致的资源浪费。
以上总结涵盖了Redis持久化机制的核心内容,包括持久化方案的选择、触发方式、优缺点比较,以及AOF重写机制的演变,旨在为用户提供一个全面的Redis持久化指南。
二, Redis位图(Bitmap)详细博客笔记
位图(Bitmap)基础
位图是一种数据结构,它使用位(bit)来表示信息。在Redis中,位图不是作为一个独立的数据类型存在,而是通过字符串(String)类型实现的。每个字符串可以看作是一个位的集合,每个字符代表8位,因此一个512MB大小的字符串可以存储(512 \times 1024 \times 1024 \times 8 = 2^{32})个位。
1.1 位图的优势
- 空间效率:位图非常适合存储大量的布尔值,因为它只占用每个状态1比特的空间。
- 性能:位图操作通常非常快速,因为它们只涉及简单的位运算。
- 原子性:Redis的位图操作是原子的,这意味着它们在并发环境下是安全的。
位图操作命令
2.1 SETBIT - 设置位的值
SETBIT key offset value命令用于设置或清除字符串中特定偏移量的位。
- key:位图对应的键。
- offset:位偏移量,从0开始计数。
- value:要设置的位值,可以是0或1。
示例:
127.0.0.1:7000> flushall # 清空所有键和数据
OK
127.0.0.1:7000> setbit k1 1 1 # 为键 k1 的第 1 位(从 0 开始计数)设置值为 1
0 # 返回值为 0,表示该位之前是 0
127.0.0.1:7000> get k1 # 获取 k1 的值
@ # 显示 k1 的二进制表示,第一个字符的第二位被设置为 1,ASCII 表示为 '@'
127.0.0.1:7000> setbit k1 7 1 # 为键 k1 的第 7 位设置值为 1
0 # 返回值为 0,表示该位之前是 0
127.0.0.1:7000> get k1 # 再次获取 k1 的值
A # 显示 k1 的二进制表示,现在第一个字符的第二位和第七位都是 1,ASCII 表示为 'A'
127.0.0.1:7000> setbit k1 7 2 # 尝试为键 k1 的第 7 位设置值为 2(错误操作,因为位值只能是 0 或 1)
ERR bit is not an integer or out of range # 返回错误信息,位值不是整数或超出范围

示例:
127.0.0.1:7000> setbit k1 9 1 # 为键 k1 的第 9 位(从 0 开始计数)设置值为 1
0 # 返回值为 0,表示该位之前是 0
127.0.0.1:7000> get k1 # 获取 k1 的值
A # 显示 k1 的二进制表示,现在第一个字符的第二位、第七位和第九位都是 1,ASCII 表示为 'A'

2.2 GETBIT - 获取位的值
GETBIT key offset命令用于获取字符串中特定偏移量的位值。
127.0.0.1:7000> getbit k1 7 # 获取键 k1 的第 7 位的值
1 # 返回 1,表示第 7 位是设置的
127.0.0.1:7000> getbit k1 8 # 获取键 k1 的第 8 位的值
0 # 返回 0,表示第 8 位是未设置的
127.0.0.1:7000> getbit k1 1 # 获取键 k1 的第 1 位的值
1 # 返回 1,表示第 1 位是设置的

2.3 BITPOS - 查找位值首次出现的下标
BITPOS key bit [start] [end]命令用于返回指定值(0或1)在指定区间上首次出现的下标。
示例1:
127.0.0.1:7000> keys * # 查看当前数据库中的所有键
k1 # 输出显示有一个键名为 "k1"
127.0.0.1:7000> bitpos k1 1 # 查找键 k1 中第一个为 1 的位的位置
1 # 输出显示第一个为 1 的位在位置 1(从 0 开始计数)
127.0.0.1:7000> setbit k1 1 0 # 将键 k1 的第 1 位的值设置为 0
1 # 输出显示此操作之前该位为 1
127.0.0.1:7000> bitpos k1 1 # 再次查找键 k1 中第一个为 1 的位的位置
7 # 输出显示现在第一个为 1 的位在位置 7
127.0.0.1:7000> setbit k1 7 0 # 将键 k1 的第 7 位的值设置为 0
1 # 输出显示此操作之前该位为 1
127.0.0.1:7000> bitpos k1 1 # 再次查找键 k1 中第一个为 1 的位的位置
9 # 输出显示现在第一个为 1 的位在位置 9
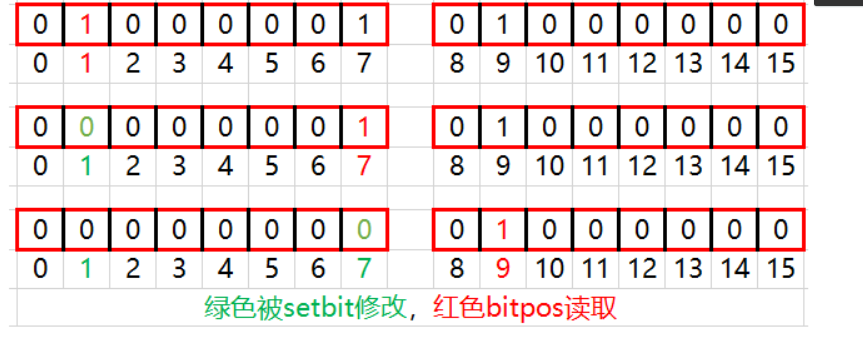
示例2:
127.0.0.1:7000> bitpos k1 1 0 0 # 在k1的第1个字节中查找值为1的首次出现的下标
1 # 返回1,表示在第1个字节中找到了值为1的位
127.0.0.1:7000> bitpos k1 1 0 # 从第1个字节开始查找值为1的首次出现的下标,直到字符串末尾
1 # 返回1,表示从第1个字节开始找到了值为1的位
127.0.0.1:7000> setbit k1 1 0 # 将k1的第1位的值设置为0
1 # 返回1,表示之前该位是1
127.0.0.1:7000> bitpos k1 1 0 0 # 再次在k1的第1个字节中查找值为1的首次出现的下标
7 # 返回7,表示在第1个字节中下一个值为1的位在位置7
127.0.0.1:7000> bitpos k1 1 0 # 再次从第1个字节开始查找值为1的首次出现的下标,直到字符串末尾
7 # 返回7,表示从第1个字节开始下一个值为1的位在位置7
127.0.0.1:7000> setbit k1 7 0 # 将k1的第7位的值设置为0
1 # 返回1,表示之前该位是1
127.0.0.1:7000> bitpos k1 1 0 0 # 在k1的第1个字节中查找值为1的首次出现的下标
-1 # 返回-1,表示在第1个字节中没有找到值为1的位
127.0.0.1:7000> bitpos k1 1 0 # 从第1个字节开始查找值为1的首次出现的下标,直到字符串末尾
9 # 返回9,表示从第1个字节开始下一个值为1的位在位置9
127.0.0.1:7000> bitpos k1 1 0 1 # 在k1的第1和第2个字节中查找值为1的首次出现的下标
9 # 返回9,表示在第1和第2个字节中值为1的位在位置9
127.0.0.1:7000> bitpos k1 1 0 2 # 在k1的第1到第3个字节中查找值为1的首次出现的下标
9 # 返回9,表示在第1到第3个字节中值为1的位在位置9,尽管数据只有2个字节,操作仍然有效
2.4 BITOP - 位操作
BITOP operation destkey sourcekey1 [sourcekey2 ...]命令用于对多个键进行位操作,并将结果保存到destkey。
- operation:操作类型,可以是AND, OR, XOR, NOT。
- destkey:目标键,存储位操作的结果。
- sourcekey:源键,进行位操作的键。
示例1::
127.0.0.1:7000> flushall # 清空Redis中的所有数据
OK # 返回OK表示操作成功
127.0.0.1:7000> keys * # 查看当前数据库中的所有键
(empty list or set) # 返回空列表,表示数据库中没有键
127.0.0.1:7000> setbit k1 1 1 # 对键k1的第1位(从0开始计数)设置值为1
(integer) 0 # 返回0表示该位之前是0,现在被设置为1
127.0.0.1:7000> setbit k2 7 1 # 对键k2的第7位(从0开始计数)设置值为1
(integer) 0 # 返回0表示该位之前是0,现在被设置为1
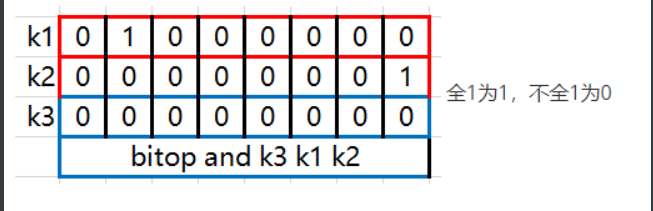
127.0.0.1:7000> bitop and k3 k1 k2 # 对k1和k2执行AND位操作,结果存储在k3
(integer) 1 # 返回1表示操作成功,且结果字符串非空
127.0.0.1:7000> get k3 # 获取k3的值
"\x00" # 返回"\x00",表示k3的字符串值为空(所有位均为0)
示例2::
127.0.0.1:7000> bitop or k4 k1 k2 # 对键k1和k2执行OR位操作,结果存储在k4
(integer) 1 # 返回1表示操作成功,且结果字符串非空
127.0.0.1:7000> get k4 # 获取k4的值
"A" # 返回"A",表示k4的字符串值在ASCII中对应的是65,二进制为01000001,即第1位和第7位是1
示例3::
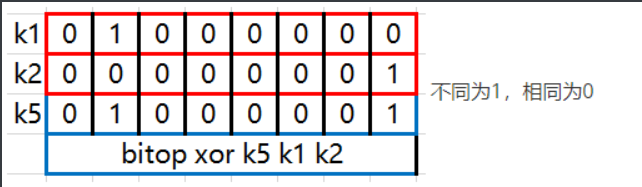
127.0.0.1:7000> bitop xor k5 k1 k2 # 对键k1和k2执行XOR(异或)位操作,结果存储在k5
(integer) 1 # 返回1表示操作成功,且结果字符串非空
127.0.0.1:7000> get k5 # 获取k5的值
"A" # 返回"A",表示k5的字符串值在ASCII中对应的是65,二进制为01000001
在异或操作中,当两个对应的位相同时结果为0,不同为1。由于k1的第1位是1,k2的第7位是1,且假设其他位都是0(因为之前的操作没有改变其他位),异或结果在第1位和第7位上都是1,因此二进制表示为01000001,对应ASCII字符"A"。
示例4::
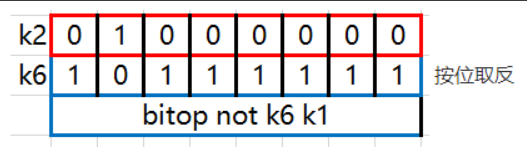
127.0.0.1:7000> bitop not k6 k1 # 对键k1执行NOT位操作,结果存储在k6
(integer) 1 # 返回1表示操作成功,且结果字符串非空
127.0.0.1:7000> get k6 # 获取k6的值
"\xbf" # 返回"\xbf",表示k6的字符串值是二进制位的反转结果
NOT操作会将所有位取反,即0变成1,1变成0。由于get命令显示的是字符的ASCII表示,所以取反后的位会对应不同的ASCII字符。在这里,"\xbf"是取反后的结果,其中\xbf是二进制位取反后对应的十六进制表示。
2.5 BITCOUNT - 统计位值的数量
BITCOUNT key [start] [end]命令用于统计字符串中值为1的位的数量。
示例1::
127.0.0.1:7000> get k1 # 获取键k1的值
"@" # 返回"@",表示k1的字符串值。"@"的ASCII码是64,二进制为01000000
127.0.0.1:7000> bitcount k1 # 统计k1中值为1的位的数量
(integer) 1 # 返回1,表示目前k1中只有一个位是1(第8位)
127.0.0.1:7000> setbit k1 7 1 # 将k1的第7位设置为1
(integer) 0 # 返回0,表示该位之前是0
127.0.0.1:7000> bitcount k1 # 再次统计k1中值为1的位的数量
(integer) 2 # 返回2,表示现在k1中有两个位是1(第7位和第8位)
127.0.0.1:7000> setbit k1 9 1 # 将k1的第9位设置为1
(integer) 0 # 返回0,表示该位之前是0
127.0.0.1:7000> bitcount k1 # 再次统计k1中值为1的位的数量
(integer) 3 # 返回3,表示现在k1中有三个位是1(第7位、第8位和第9位)
127.0.0.1:7000> bitcount k1 0 0 # 统计k1中第1个字节内值为1的位的数量
(integer) 2 # 返回2,表示第1个字节中有两个字是1(第7位和第8位)
127.0.0.1:7000> bitcount k1 0 1 # 统计k1中从第1个字节到第2个字节内值为1的位的数量
(integer) 3 # 返回3,表示从第1个字节到第2个字节中有三个字是1(第7位、第8位和第9位)
bitcount res2 0 1 # 这行看起来像是一个注释或命令的一部分,可能是想再次执行bitcount操作,但是不完整
请注意,bitcount命令的start和end参数是以字节为单位的,而不是位。所以bitcount k1 0 0实际上统计的是第一个字节中1的总数,而bitcount k1 0 1统计的是第一个字节加上第二个字节(如果有的话)中1的总数。在这个例子中,由于k1的数据不足两个字节,所以bitcount k1 0 1实际上和bitcount k1 0 0的结果是一样的。
示例2::
127.0.0.1:7000> BITCOUNT k1 0 -1 # 使用BITCOUNT命令统计k1中从第0个字节开始到结束(-1表示最后一个字节)的1的总数
(integer) 3 # 返回3,表示在整个字符串k1中,共有3个位的值为1
这条命令等同于BITCOUNT k1,因为不指定start和end参数时,默认会对整个字符串进行统计。在这里,它统计了键k1中所有字节里值为1的位的总数,并返回了结果3。
示例3::
127.0.0.1:7000> set k7 ab # 将字符串"ab"设置为键k7的值
OK # 返回OK表示设置成功
127.0.0.1:7000> get k7 # 获取键k7的值
"ab" # 返回字符串"ab"
127.0.0.1:7000> bitcount k7 # 统计k7中所有字节中1的总数
(integer) 6 # 返回6,表示字符串"ab"的二进制表示中共有6个位的值为1
127.0.0.1:7000> bitcount k7 0 0 # 统计k7中第1个字节("a"的ASCII码)中1的总数
(integer) 3 # 返回3,表示"a"的二进制表示(01100001)中有3个位的值为1
127.0.0.1:7000> bitcount k7 1 1 # 统计k7中第2个字节("b"的ASCII码)中1的总数
(integer) 3 # 返回3,表示"b"的二进制表示(01101110)中有3个位的值为1
这里解释一下bitcount命令的用法和结果:
- ASCII字符
"a"的二进制表示为01100001,其中有3个位的值为1。 - ASCII字符
"b"的二进制表示为01101110,其中有3个位的值为1。 - 因此,对于
bitcount k7 0 0,它统计的是第一个字节(即"a")中值为1的位数,结果是3。 - 对于
bitcount k7 1 1,它统计的是第二个字节(即"b")中值为1的位数,结果也是3。

示例4::
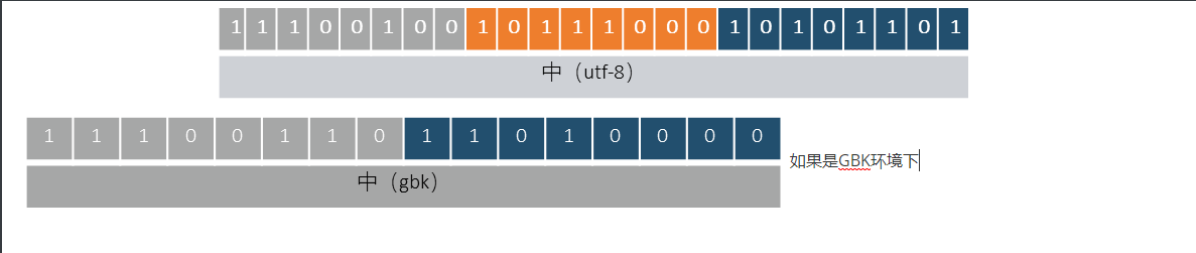
127.0.0.1:7000> set k8 中 # 将字符串"中"设置为键k8的值
OK # 返回OK表示设置成功
127.0.0.1:7000> bitcount k8 # 统计k8中所有字节中1的总数
(integer) 13 # 返回13,表示字符串"中"的二进制表示中共有13个位的值为1
127.0.0.1:7000> get k8 # 获取键k8的值
"\xe4\xb8\xad" # 返回字符串"\xe4\xb8\xad",这是"中"的UTF-8编码
这里解释一下bitcount命令的结果:
- 字符串"中"在UTF-8编码下由三个字节组成:
"\xe4\xb8\xad"。 - UTF-8编码的"中"的第一个字节
"\xe4"(二进制为11100100)中有4个位的值为1。 - 第二个字节
"\xb8"(二进制为10111000)中有3个位的值为1。 - 第三个字节
"\xad"(二进制为10101101)中有6个位的值为1。 - 因此,对于
bitcount k8,它统计的是三个字节中所有值为1的位数,总计是4+3+6=13。
位图应用场景
3.1 用户签到统计
用户ID为key,天作为offset,上线置为1 366> 000000000000000
366 /8=46Byte ID为18的用户,今年的第1天签到、第30天签到
示例:
127.0.0.1:7000[2]> setbit u18 1 1 # 为用户ID为18的键u18的第1位设置值为1
(integer) 0 # 返回0,表示该位之前是0,现在被设置为1
127.0.0.1:7000[2]> setbit u18 30 1 # 为用户ID为18的键u18的第30位设置值为1
(integer) 0 # 返回0,表示该位之前是0,现在被设置为1
127.0.0.1:7000[2]> bitcount u18 # 统计键u18中值为1的位的总数,即用户ID为18的签到总次数
(integer) 2 # 返回2,表示用户ID为18的用户总共签到了2次
127.0.0.1:7000[2]> keys u* # 查找所有以u开头的键
1) "u18" # 返回结果,只有一个键"u18"
3.2 活跃用户统计
天作为key,用户ID为offset,上线置为1
求一段时间内活跃用户数 5000 0000 / 8366= 6.3MB=366 (五千万活跃用户1年才产生2GB左右的数据)
位图可以用来统计每天的活跃用户数,每天一个位图,每个用户ID对应一个位。
示例:
127.0.0.1:7000> SETBIT 20190601 5 1 # 为键20190601的第5位设置值为1,表示有用户在6月1日活跃
# 0000 0100
127.0.0.1:7000> SETBIT 20190602 7 1 # 为键20190602的第7位设置值为1,表示有用户在6月2日活跃
# 0000 0001
127.0.0.1:7000> SETBIT 20190603 7 1 # 为键20190603的第7位设置值为1,表示有用户在6月3日活跃
# 0000 0001
求6月1日到6月10日的活跃用户数
127.0.0.1:7000> BITOP OR users 20190601 20190602 20190603 ... 20190610 # 对6月1日到6月10日的活跃用户数据执行OR位操作,结果存储在users
127.0.0.1:7000> BITCOUNT users # 统计users中值为1的位的总数,即这段时间内的总活跃用户数
结果为2 # 返回2,表示在6月1日到6月10日这段时间内,共有2个不同的用户活跃过
这段操作首先将特定日期的特定位设置为1,以标记活跃用户。然后,使用BITOP OR命令将这些日期的数据合并,以找出这段时间内所有活跃的用户。最后,使用BITCOUNT命令统计合并后数据中值为1的位的总数,得到总活跃用户数。
3.3 用户在线状态跟踪
位图可以用来跟踪用户的在线状态,每个用户对应一个位,1表示在线,0表示离线。
示例:
127.0.0.1:7000> SETBIT online 5 1 # 将键online的第5位设置为1,表示有用户上线,二进制表示为 0000 0100
(integer) 0 # 返回0,表示该位之前是0,现在被设置为1
127.0.0.1:7000> SETBIT online 7 1 # 将键online的第7位设置为1,表示另一个用户上线,二进制表示为 0000 0101
(integer) 0 # 返回0,表示该位之前是0,现在被设置为1
127.0.0.1:7000> bitcount online # 统计键online中值为1的位的总数,表示当前在线的用户数
(integer) 2 # 返回2,表示当前有2个用户在线
127.0.0.1:7000> SETBIT online 7 0 # 将键online的第7位设置为0,表示之前上线的用户之一现在下线了
(integer) 1 # 返回1,表示该位之前是1,现在被设置为0
127.0.0.1:7000> bitcount online # 再次统计键online中值为1的位的总数,表示当前在线的用户数
(integer) 1 # 返回1,表示现在有1个用户在线
这段操作演示了如何使用位图来跟踪用户的在线状态。通过SETBIT命令将特定用户的在线状态设置为1(上线)或0(下线),并用bitcount命令统计当前在线的用户总数。
总结
Redis位图是一种高效的数据结构,适用于需要存储大量布尔值的场景。通过位图,我们可以节省内存空间,同时享受快速的读写性能。位图的操作是原子性的,适合在并发环境中使用。通过上述命令和应用场景,我们可以充分利用位图的优势,为各种应用提供支持。