散列表(哈希表)
基本思想
以数据对象的关键字key为自变量,通过一个确定的函数关系h,计算出对应的函数值h(key),把这个值解释为数据对象的存储地址,并按此存放,即
存储位置=h(key)
装填因子
设散列表空间大小为m,填入表中的元素个数是n,则装填因子a=n/m,常见散列表大小设计使得a=0.5~0.8为宜
装填因子有什么用?
装填因子决定了散列表的负载程度。装填因子越大,散列表的负载越重,冲突的概率也越高,查找性能可能会下降;
反之,装填因子越小,冲突的概率就越低,但散列表的空间利用率也会降低。
同义词
映射到同一散列地址上的关键字称为同义词
散列函数的构造方法
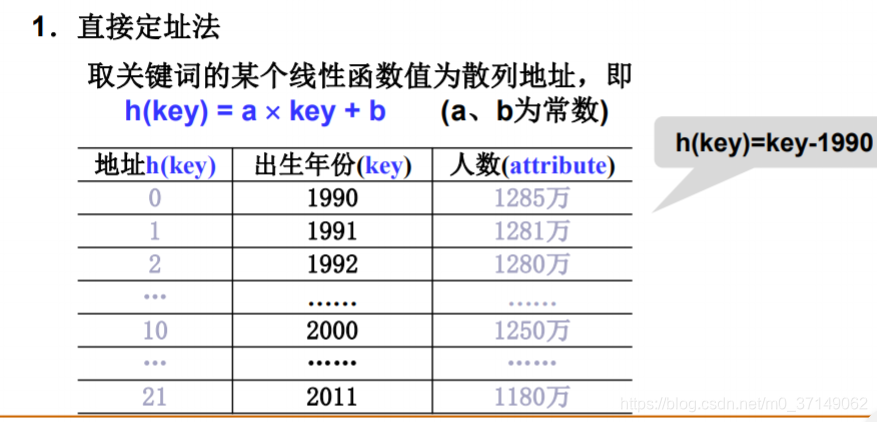
直接定址法
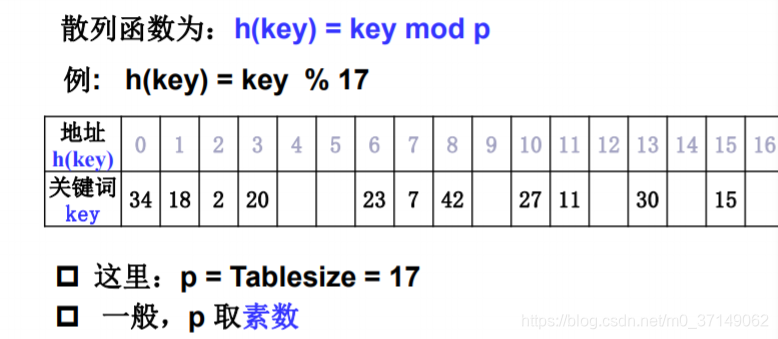
除留取余法
常用方法,假设散列表长为TableSize(TableSize的选取,通常由关键词的大小n和允许最大装填因子a决定,一般将TableSize取n/a),选择一个正整数p<=TableSize,散列函数为:
h(key)=key mod p
除此之外,还有很多方法。