homework1.2
输出网络结构,使用CNN,由卷积层,池化层和全连接层构成

将图像转化成tensor的时候做了简单的数据增强
# 数据预处理和数据增强
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
在训练时加入了权重衰减和学习率调度
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) # 添加权重衰减
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1) # 学习率调度

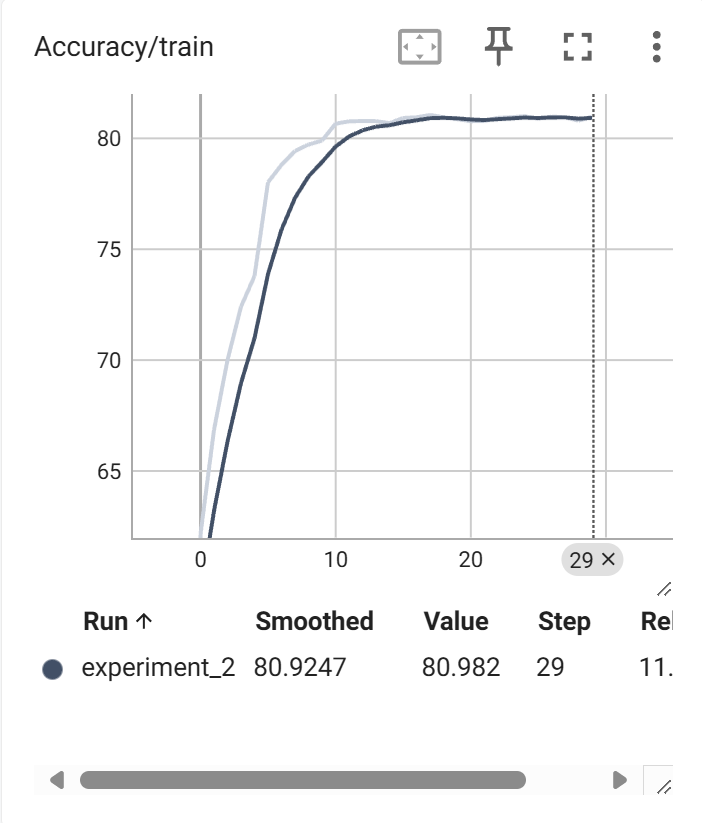
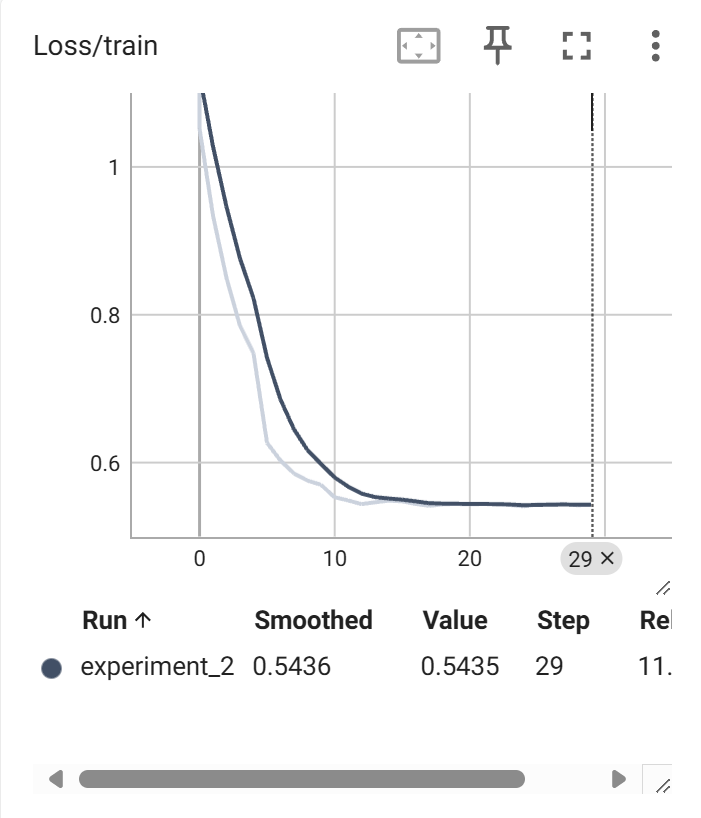
使用tensorboard完成训练时的可视化
writer.add_scalar('Loss/train', sum_loss/len(train_loader), epoch)
writer.add_scalar('Accuracy/train', accuracy, epoch)
完成在验证集上的精度测试
def evaluate(model, dataloader, device):
# 切换到推理模式
model.eval()
correct = 0
total = 0
# 禁用梯度计算
with torch.no_grad():
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return accuracy
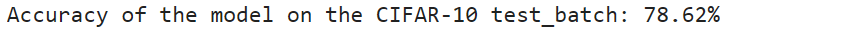
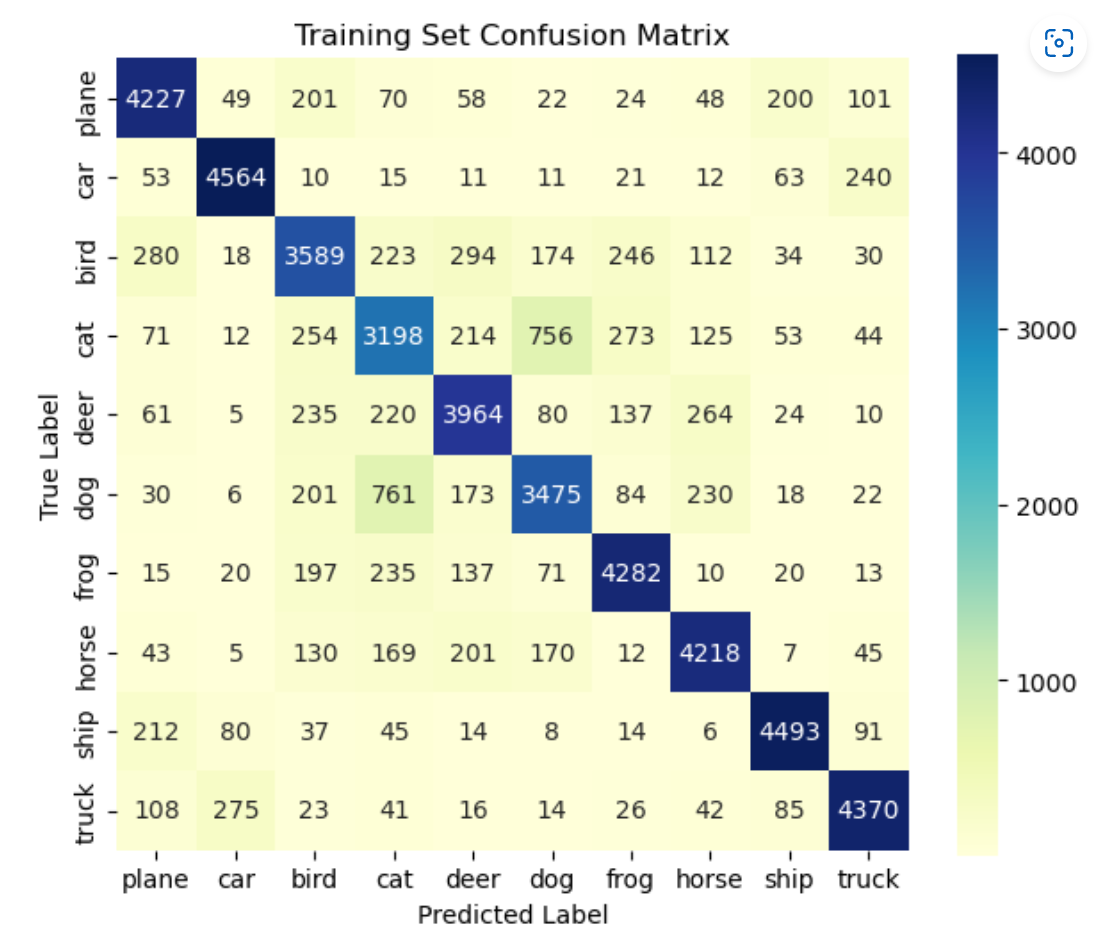
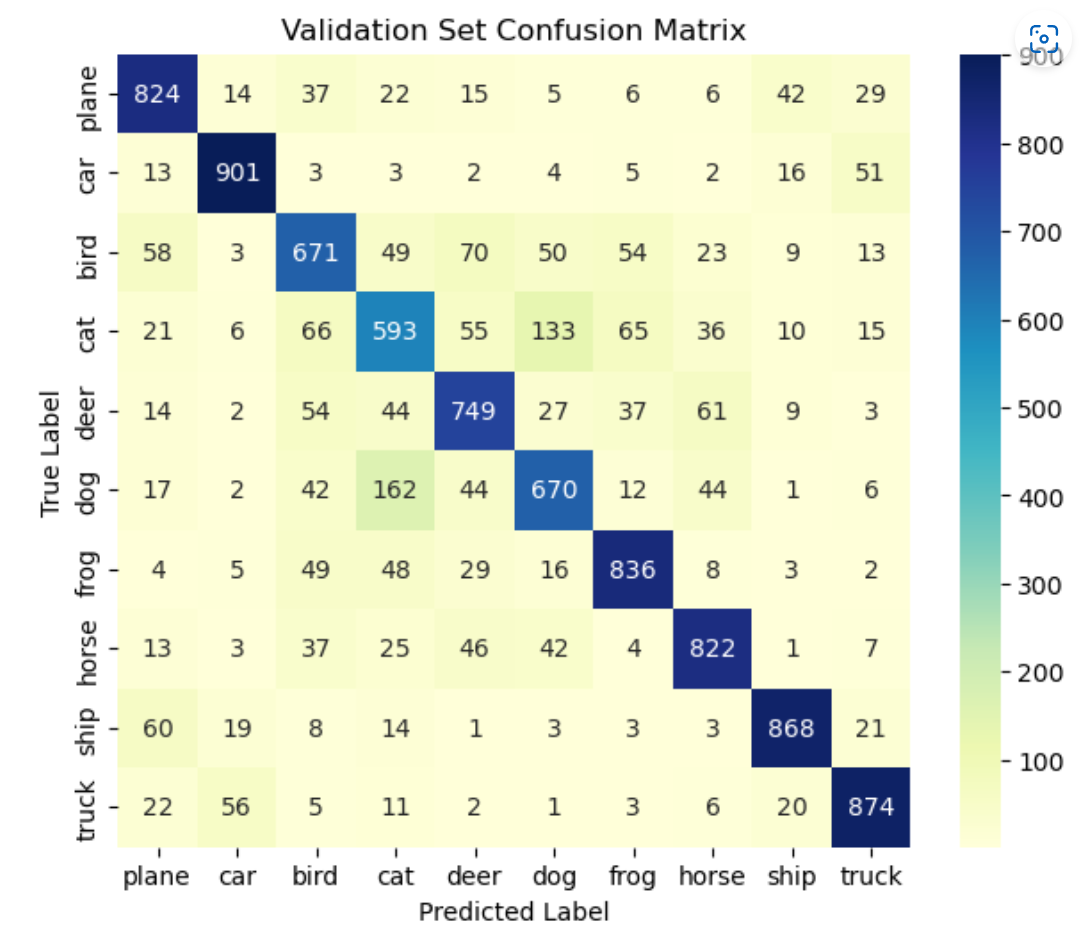
绘制混淆矩阵(get_predictions函数由GPT生成)
train_labels, train_preds = get_predictions(model, train_loader, device)
val_labels, val_preds = get_predictions(model, test_loader, device)
# 计算混淆矩阵
train_confm = confusion_matrix(train_labels, train_preds)
val_confm = confusion_matrix(val_labels, val_preds)
分析网络参数
网络深度
当深度浅时,参数较少,训练更快,适合处理简单的问题,对于复杂的模式识别问题,容易出现欠拟合
当深度深时,可以学习更复杂的特征,具有更好的泛化能力,但过深的网络可能导致梯度消失或梯度爆炸使得模型难以收敛
激活函数
ReLU:计算简单,收敛快,但当梯度过小时,神经元不再更新权重
Sigmoid:适合二分类问题,当梯度接近0时,容易导致梯度消失问题,不适合深层网络
神经元数量
神经元较少,模型参数少,计算速度快,存储需求小,适合处理简单问题或小数据集,可能导致欠拟合,无法学习到足够的特征
神经元较多,模型的容量增加,能够捕捉更多的细节和复杂的特征,可能导致过拟合,还会增加计算成本和内存需求
Softmax()
在损失函数为交叉熵时CrossEntropyLoss()里已经内嵌了softmax()层,无法比较是否使用对训练效果的影响
softmax()函数将网络的输出转换为一个概率分布,广泛应用于多分类任务中,同时softmax() 具有很好的梯度性质,能够平滑地更新模型的参数