Redis-cluster windows搭建
一、Redis cluster 搭建步骤
1、Buby环境搭建以及Redis安装
- zlib安装
i. 下载地址:http://zlib.net/
ii. tar xf zlib-1.2.11.tar.gz –C /usr/local/src
iii. cd /usr/local/src/zlib-1.2.11/
iv. ./configure
v. make && make install
- ruby安装
i. 下载地址:http://www.ruby-lang.org/en/downloads/
ii. tar xf ruby-2.4.5.tar.gz –C /usr/local/src
iii. cd /usr/local/src/ruby-2.4.5/
iv. ./configure
v. make && make install
vi. ln -s /usr/local/ruby/bin/ruby /usr/cd /bin
- rubygems安装
i. 下载地址:https://rubygems.org/pages/download
ii. tar xf rubygems-2.7.8.tgz –C /usr/local/src
iii. cd /usr/local/src/rubygems-2.7.8/
iv. ruby setup.rd
- redis-4.0.3.gem安装
i. 下载地址:https://rubygems.org/gems/redis/versions
ii. gem install --local redis-3.3.3.gem
- redis安装
i. 下载地址:http://www.redis.cn/
ii. tar xf redis-5.0.2.tar.gz –C /usr/local/src
iii. cd /usr/local/src/redis-5.0.2/
iv. make && make install
2、Redis集群搭建,直接在本机起6个redis作为集群
- 新建6个node目录
i. cd /usr/local/src/redis-5.0.2/
ii. mkdir node1 node2 node3 node4 node5 node6
- 修改配置文件支持集群
i. cd /usr/local/src/redis-5.0.2/
ii. cp redis.conf node1/
iii. cd node1/
iv. vi redis.conf
- port 7001
- daemonize yes
- cluster-enabled yes
- cluster-config-file nodes.conf
- cluster-node-timeout 1000 ->默认是15000,15秒,为了快速master/slave切换效果,设定为1秒
- appendonly yes
- bind 127.0.0.1
- 将node1的配置文件修改对应的node的序号分发到其余node节点
i. cd /usr/local/src/redis-5.0.2/
ii. cp node1/redis.conf node2, cp node1/redis.conf node3, …
iii. vi node2/redis.conf, vi node3/redis.conf, …
- port 7002/3/4/5/6
- 分别sartup各个node的service
i. cd node1, cd node2…
ii. redis-server redis.conf
- 将以上启动的服务进行集群配置
i. redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1;
- 测试集群
i. redis-cli –p 7001 –c, 一定要添加-c参数,否则不会进入进群环境
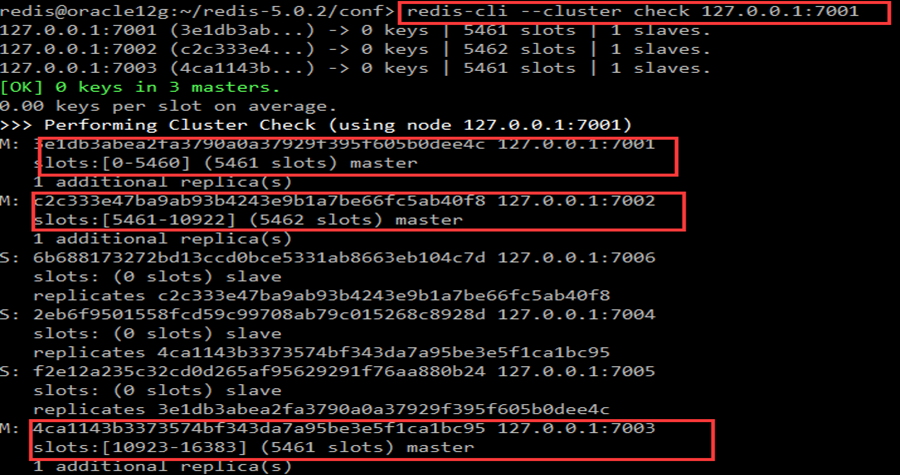
ii. cluster nodes 参看集群各个节点情况

- 红框显示master的node id与slave对应的master id
- 留意所有master的slot是连续的,0 - 4095, 4096 – 8191, 8192 – 12287, 12288 - 16383
iii. cluster info
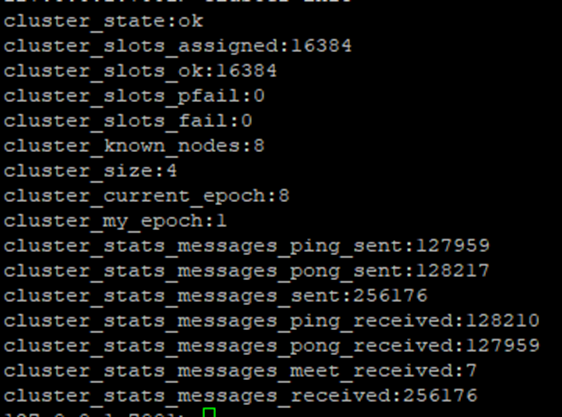
- 显示集群的状态,有多少个node以及各个node的情况
- 关闭集群
i. 分别关闭各个node的service
- redis-cli –p 700x shutdown
- 重建集群
i. 分别关闭各个node的service
- redis-cli –p 700x shutdown
ii. 分别删除各个node文件夹下面的nodes.conf, dump.rdb, appendonly.aof文件
- rm –f /nodex/nodes.conf dump.rdb appendonly.aof
iii. 分别开启节点service
- cd nodex
- redis-server redis.conf
iv. 重建集群
- redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1;
- 集群后的HA
i. 以6个节点分别部署在三台(1,2,3)物理PC上
ii. 分别用A,B,C代表三个master节点,对应的slave节点用a,b,c表示
iii. 由于同组的master与slave down会导致整个集群不可用(slot 无法transfer到其他节点),所以将各自的master与slave分配到不同的PC上,如下图
iv. 假设其中一部PC发生宕机,如PC 2宕机,则PC 3的slave b会升级为master B,继续保持集群可用,如下图
v. 保证集群继续可以保持HA,需要补充一台物理PC,假设是4,将PC 2的B与a的节点的目录,包括(redis.conf, node.conf, dump.rdb, appendonly.aof)文件抄过去并start
vi. 保证不同master与同组的master与slave分开原则,将PC 3的B 进行一次shutdown,然后再start,最终恢复正常的集群服务
- 深入测试总结
i. 集群需要最少6个节点,3个master,3个slave
ii. 集群后>=50%的master节点down,则整个集群服务不可用
- 3个master down 1个,集群服务正常
- 3个master down 2个,集群服务不正常
- 4个master down 2个,集群服务不正常
- 5个master down 2个,集群服务正常
iii. 集群后其中一个master与跟这个master相关联的所有slave down,整个集群服务不可用
- 其他有关集群的操作指令
i. 增加节点
- redis-cli --cluster add-node [source cluster ip]:[source cluster port] [destination ip]:[destination port]
ii. 删除节点
- redis-cli --cluster del-node [source cluster ip]:[source cluster port] [node id]
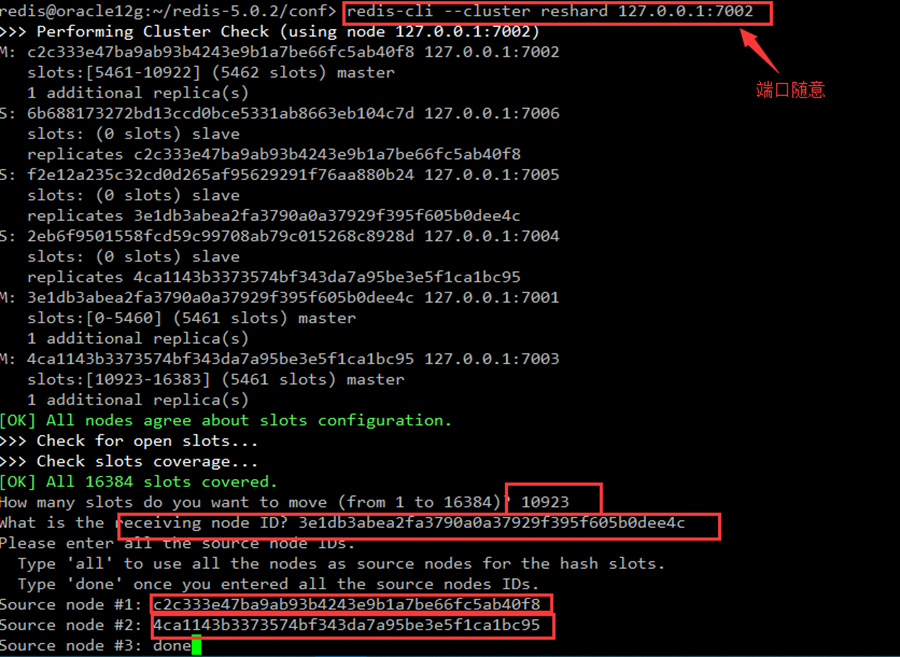
iii. 将即将删除节点插槽slot移动到其他节点,前提是所有节点都需要在线状态
- redis-cli --cluster reshard [source cluster ip]:[source cluster port]
- 输入需要移动的插槽,一般对应node id的插槽数量
- 输入插槽移入的node id
- 输入需要删除的node id
- 需要结束的时候输入done即可
iv. 将slave更变递属的master
- 用改slave的ip与port登入,如redis-cli –h 192.168.1.49 –p 7004 –c
- cluster replicate [switch to master node id]
v. clustersaveconfig:将节点的配置文件保存到硬盘里面。
二、常见错误解决
ERROR: Error installing redis redis requires Ruby version >= 2.2.2
解决;安装rvm 升级ruby 上面有流程
ERROR: SSL connect error
解决: 无法在服务器使用curl命令访问https域名,原因是nss版本有点旧了,yum -y update nss更新一下,重新curl即可!
ERROR
解决:启动至少需要3个master节点,至少6个节点,
解决:删除节点需要启动该节点 把槽分配出去
Error:Node is not empty
rm –rf dump.rdb nodes-7006.conf appendonly.aof
再重启节点
解决:删除的节点占用了槽,需要重新分配
三、RDB 和 AOF区别(官方文档)
RDB:RDB持久性在指定的时间间隔执行数据集的时间点快照
RDB 优点
- RDB是Redis数据的一个非常紧凑的单文件时间点表示。RDB文件非常适合备份。例如,您可能希望在最近24小时内每小时归档RDB文件,并在30天内每天保存一个RDB快照。这允许您在发生灾难时轻松地恢复数据集的不同版本。
- rdb非常适合灾难恢复,单个压缩文件可以传输到远程数据中心,或Amazon S3(可能加密)。
- rdb最大化了Redis的性能,因为Redis父进程为了持久化需要做的唯一工作就是分配一个子进程,而子进程将完成所有的工作。父实例永远不会执行磁盘I/O或类似的操作。
RDB缺点
- 如果您需要在Redis停止工作(例如断电后)的情况下最小化数据丢失的机会,那么RDB是不好的。您可以在生成RDB的地方配置不同的保存点(例如,至少在5分钟后对数据集进行100次写操作,但是您可以有多个保存点)。但是,您通常每5分钟或更长时间创建一个RDB快照,因此,如果Redis停止工作而没有正确地关闭,您应该准备好丢失最新的几分钟数据。
- RDB通常需要fork(),以便使用子进程将其持久化到磁盘上。如果数据集很大,Fork()可能会很耗时,如果数据集很大,CPU性能不太好,那么Redis可能会在一毫秒甚至一秒内停止为客户机提供服务。AOF还需要fork(),但是您可以调优重写日志的频率,而不需要牺牲持久性。
AOF: AOF持久性记录服务器接收到的每个写操作,这些写操作将在服务器启动时再次播放,重新构造原始数据集。命令使用与Redis协议本身相同的格式,以一种仅用于追加的方式进行日志记录。当日志太大时,Redis可以在后台重写日志
AOF优点
- 使用AOF Redis更持久:你可以有不同的fsync策略:完全没有fsync,每秒fsync,每次查询时fsync。在默认的fsync策略下,每秒钟的写入性能仍然很好(fsync是使用后台线程执行的,在没有fsync的情况下,主线程会尝试执行写入),但是您只能损失一秒钟的写入时间。
- AOF日志只是一个附加的日志,所以没有查找,也没有断电时的损坏问题。即使日志由于某种原因(磁盘已满或其他原因)以半写的命令结束,redis-check-aof工具也能够轻松地修复它。
- 当AOF过大时,redis能够自动重写背景中的AOF。重写是完全安全,复述,继续追加到旧文件,产生一个全新的最小集合操作需要创建当前数据集,而一旦准备复述,开关的两个和第二个文件附加到新的一个开始。
- aof以一种易于理解和解析的格式,一个接一个地记录所有操作。您甚至可以很容易地导出AOF文件。例如,即使您使用FLUSHALL命令刷新了所有错误,如果在此期间没有执行日志重写,您仍然可以保存数据集,只需要停止服务器、删除最新命令并再次启动Redis。
AOF缺点
- 对于相同的数据集,aof文件通常大于等效的RDB文件。
- aof可能比RDB慢,这取决于具体的fsync策略。一般来说,fsync设置为每秒,性能仍然很高,如果禁用fsync,即使在高负载下,速度也应该和RDB一样快。尽管如此,RDB仍然能够提供更多关于最大延迟的保证,即使在写负载很大的情况下。
- 在过去,我们在特定命令中遇到过罕见的bug(例如,有一个涉及到像BRPOPLPUSH这样的阻塞命令),导致生成的AOF在重新加载时不能完全复制相同的数据集。这种bug很少见,我们在测试套件中有测试自动创建随机的复杂数据集,并重新加载它们以检查是否一切正常,但是这种bug在RDB持久性下几乎是不可能的。为了更清楚地说明这一点:Redis AOF可以增量地更新现有状态,就像MySQL或MongoDB那样,而RDB快照一次又一次从头创建一切,这在概念上更健壮。然而- 1)需要注意的是,每次AOF是重写的复述,从头重新创建从实际数据中包含的数据集,使错误更强而总是附加阻力AOF文件(或一个重写阅读旧AOF代替阅读数据在内存中)。2)我们从来没有收到过来自用户的关于在现实世界中检测到的AOF腐败的报告。
四 实施方案要点
Part1:集群对于不同组的使用方式
1、Redis集群是单用户登录,并不存在多用户登录
2、Redis集群里面数据是根据crc16算法分配到对应的哈希槽的,没有具体域的划分
所以考虑用前缀划分如:FO.key \BO.key \Web.key
Part2:非集群系统数据迁移到集群系统
1、非集群系统数据利用指令BGREWRITEAOF更新一份.aof文件,里面包含所有redis数据
2、将以上文件复制到集群的其中一个节点,然后将集群上其余节点的卡槽(slots)迁移到该节点上,数据覆盖到该节点
3将上述节点重新分配卡槽到其余的节点上(redis-cli –cluster reshard)。
具体操作:step1、操作非集群系统,检查数据量并且获取最新的.aof文件

step2、操作redis集群,把其余节点所有slots(槽)都分配到一个节点上
查看集群slots(槽)分配情况
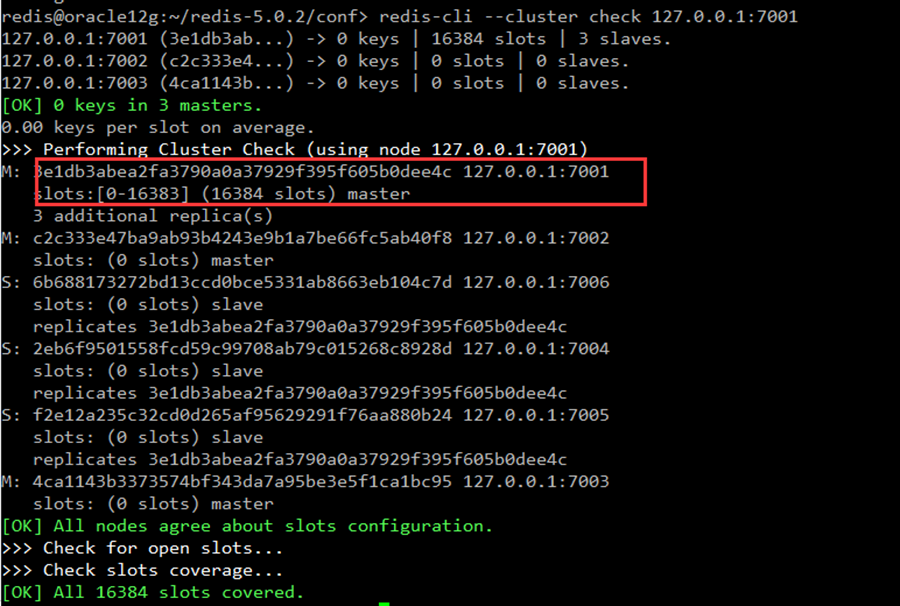
将所有槽都分配到一个节点上
分配成功


替换文件,scp rsync也可
重启该节点
数据迁移成功

Part3:集群搭建
准备4台机子 3台构建集群,1台做信息备份或者充当集群机子

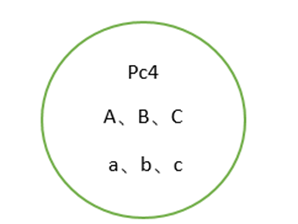
Part4:信息备份
PC1 PC2 PC3 定时推送节点的信息(redis.conf,appendonly.aof,nodes.conf)到PC4,存放目录清晰区分节点
Part5: 监测集群的安全状态
A、 可视化web界面定时监控:Redis-live 、Redis-monior(redis服务器信息、版本、上线时间、内存损耗 连接数量、请求数量等等)但是遇到问题无法自动通知到用户。
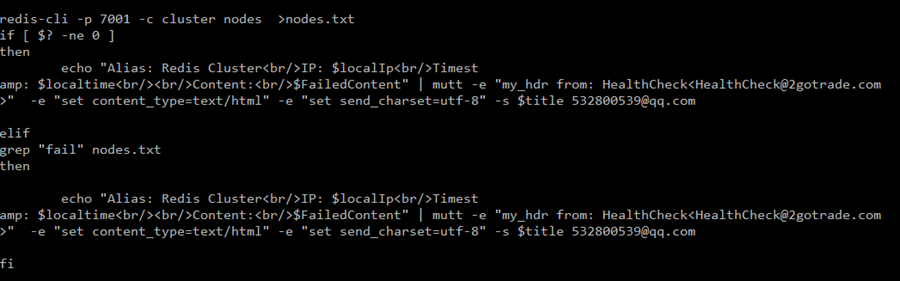
B、 通过脚本scripts定时运行监测集群的状态发现出现问题自动发送邮件提醒
Check_test.sh 脚本

定时任务
Scripts思路:每个机子定时任务配置上述脚本,通过7001端口进入集群,如果不能进入则表明节点出现问题,则发送邮件通知。如果进入后发现集群状态有fail信息,同样发送邮件通知。为什么要三台机子都同时跑这个脚本,因为如果只有一台机子跑这个脚本的话 万一这台机子挂了我们就收不了邮件,三台同时跑,等于三台机子同时检测集群状态,虽然如果出现问题我们会收到3封邮件,但我们旨在知道集群安全状态
Part6:处理宕机重启情况(还没有比较完善的方案)
PC1异常à PC1恢复à
显然,此时该集群是伪健康状态,没有按照我们设想的主从搭配进行,一旦PC3宕机整个集群就不可用了。所以从宕机到恢复,如何让主从的分配按照我们的设想进行是关键所在。
预想一个脚本 需要功能:重构redis cluster 并且主从分布符合不同master与同组的master与slave分开原则,这样一来不需要考虑每台机子的节点是主是从 或者变更情况。每次按照我们设计的规则去分布。
需要redis指令(cluster replicate (更改主从递属)、 redis-cli --cluster create(重构集群))
待测试问题:这样频繁重建集群,数据同步问题或者其他负面的影响。

五、额外:sentinel模式(非cluster模式)
Sentinel模式,健壮性很好,master挂掉会自动推举出新的master 数据都集中在一台机子上,会影响读写速度,再严重的可能会崩溃,所以数据量大的话不建议采用。
Cluster模式可以将数据分散到集群的多台机子上,扩展性比较好,节点互相通信可以自动推举出新的master,但是 集群健壮性和机子的数量成正比。
Preparation:
Redis.conf:*(1主2从1sentinel)
(master)ip:127.0.0.1 port:7001
(slave)ip:127.0.0.1 port:7002 replicaof 127.0.0.1 7001
(slave)ip:127.0.0.1 port:7003 replicaof 127.0.0.1 7001(这样可以确立主从关系,并不可以自动切换!!)
解释: 7001为主,7002 和7003都是从 递属于7001
Sentinel.conf
sentinel monitor mymaster 127.0.0.1 7001 1 (监听这个master)
sentinel known-replica mymaster 127.0.0.1 7002
sentinel known-replica mymaster 127.0.0.1 7003
(当master断掉后会切换到这里其中一个,这里不分顺序,已测试无数次)
解释:sentinel监听7001这个主 当这个挂掉之后 随机切换到7002 或者7003,后续机子同理