数据库 - 副本
数据库
数据库的基本知识
数据库的基本作用:
1 :存储大量数据,方便检索和访问
2 :保持数据信息的一致、完整
3 :共享和安全
4 :通过组合分析,产生新的有用信息
数据库的基本概念:
1 :数据库就是“数据”的“仓库”
2 :数据库由表、关系以及操作对象组成
3 :数据存放在表中
4:数据库的增删改查的功能都是由数据库管理系统—DBMS来实现
5:为减少数据查找的麻烦,允许数据有一定的冗余
6:存在不正确、不准确的数据,数据库“失去了完整性”
Oracle 数据库
主要特点:
1 :支持多用户、大事务量的事务处理
2 :数据安全性和完整性控制
3 :支持分布式数据处理
4 :可移植性
基本体系:
1 :数据库的体系结构是指数据库的组成、工作过程与原理,以及数据在数据库中的组织与管理机制
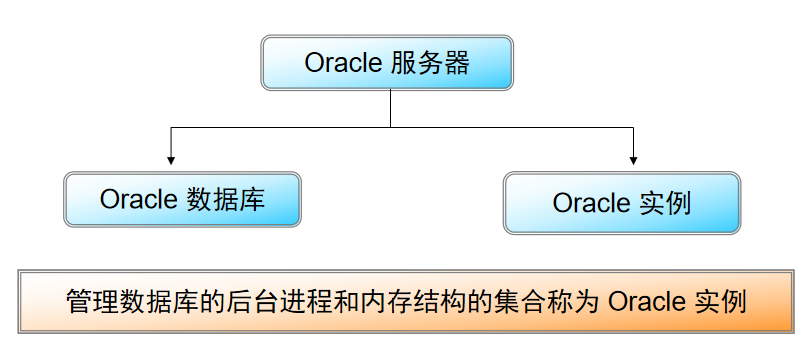
2 :Oracle服务器提供开放、全面和综合的信息管理,它由Oracle数据库和Oracle实例组成
基本结构:
1 :Oracle 数据库由操作系统文件组成,这些文件为数据库信息提供实际物理存储区
2 :Oracle 数据库包括逻辑结构和物理结构
3 :物理组件就是Oracle数据库所使用的操作系统物理文件,分别有数据文件、控制文件、日志文件(日志文件记录对数据库的所有修改信息,用于故障恢复)
4:逻辑组件如下图所示:
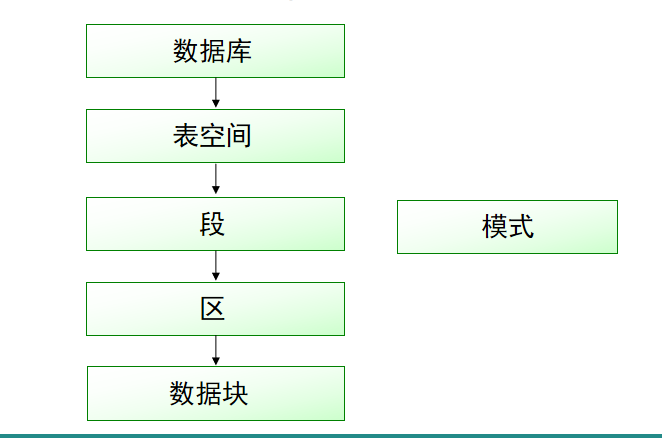
5:关于逻辑组件的解释:
(1)表空间是数据库中最大的逻辑单位,一个 Oracle 数据库至少包含一个表空间,就是名为SYSTEM的系统表空间。
(2)每个表空间是由一个或多个数据文件组成的,一个数据文件只能与一个表空间相关联。
(3)表空间的大小等于构成该表空间的所有数据文件大小之和。
(4)段 : 段是构成表空间的逻辑存储结构,段由一组区组成。 按照段所存储数据的特征,将段分为四种类型,即数据段、索引段、回退段和临时段。
(5)区 : 区为段分配空间,它由连续的数据块组成。 当段中的所有空间已完全使用时,系统自动为该段分配一个新区。区不能跨数据文件存在,只能存在于一个数据文件中。
(6)数据块 : 数据块是Oracle服务器所能分配、读取或写入的最小存储单元。Oracle服务器以数据块为单位管理数据文件的存储空间。
(7)模式 : 模式是对用户所创建的数据库对象的总称。 模式对象包括表、视图、索引、同义词、序列、过程和程序包等。
系统全局区:
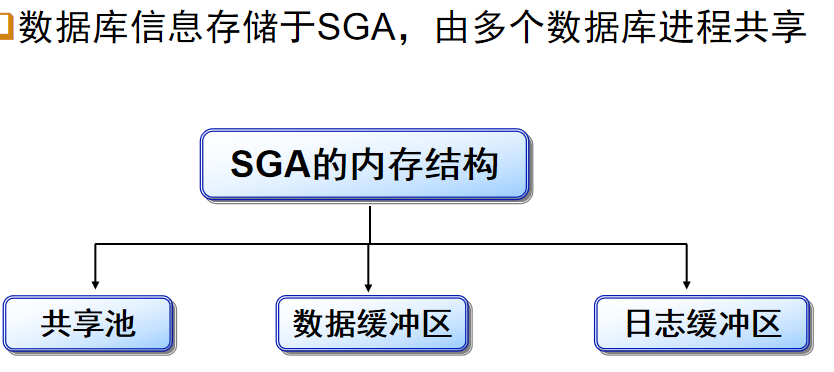
关于内存结构的解释:
共享池 :
(1)共享池是对SQL、PL/SQL程序进行语法分析、编译、执行的内存区域
(2)共享池由库缓存和数据字典缓存组成。
(3)共享池的大小直接影响数据库的性能。
数据缓冲区 :
(1)用于存储从磁盘数据文件中读入的数据,所有用户共享。
(2)服务器进程将读入的数据保存在数据缓冲区中,当后续的请求需要这些数据时可以在内存中找到,不需要再从磁盘读取,提高了读取速度。
(3)数据缓冲区的大小对数据库的读取速度有直接的影响。
日志缓冲区 :
(1)日志记录数据库的所有修改信息,日志信息首先产生于日志缓冲区。
(2)当日志缓冲区的日志数据达到一定数量时,由后台进程将日志数据写入日志文件中。
(3)相对来说,日志缓冲区对数据库的性能影响较小。
后台进程 :
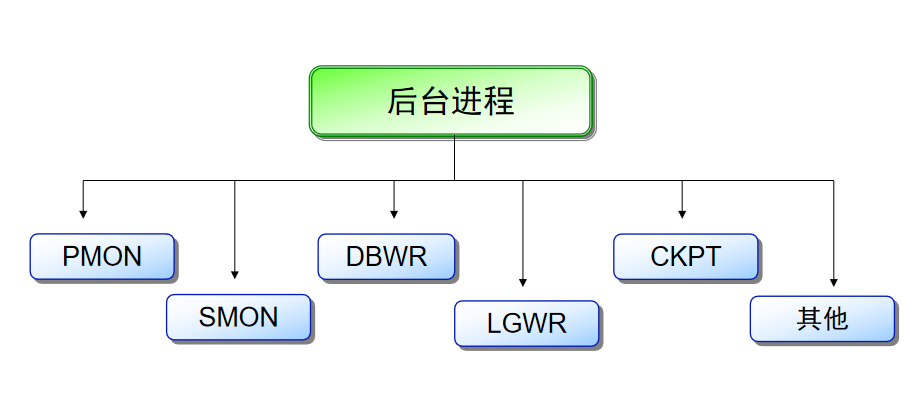
PMON 进程监控进程 :
(1)清理出现故障的进程。
(2)释放所有当前挂起的锁定。
(3)释放故障进程使用的资源。
SMON 系统监控进程 :
(1)在实例失败之后,重新打开数据库时自动恢复实例。
(2)整理数据文件的自由空间,将相邻区域结合起来。
(3)释放不再使用的临时段。
DBWR 数据写入进程 :
(1)管理数据缓冲区,将最近使用过的块保留在内存中。
(2)将修改后的缓冲区数据写入数据文件中。
LGWR 日志写入进程 :
(1)负责将日志缓冲区中的日志数据写入日志文件。
(2)系统有多个日志文件,该进程以循环的方式将数据写入文件。
CKPT 进程检查进程 :
(1)该进程在检查点出现时,对全部数据文件的标题进行修改,指示该检查点。
会话:
1 :会话是用户与 Oracle 服务器的单个连接
2 :当用户与服务器建立连接时创建会话
3 :当用户与服务器断开连接时关闭会话
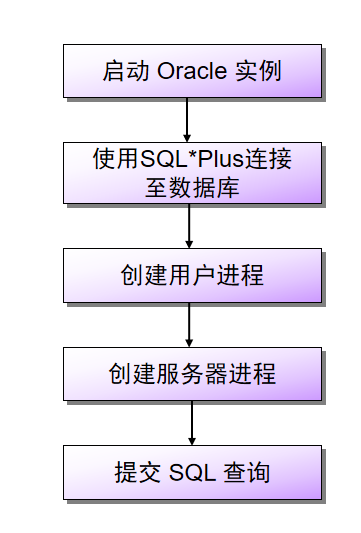
程序全局区:
1 :程序全局区(PGA)包含单个服务器进程所需的数据和控制信息
2 :PGA是在用户进程连接到数据库并创建一个会话时自动分配的,保存每个与Oracle 数据库连接的用户进程所需的信息
3 :PGA为非共享区,只能单个进程使用,当一个用户会话结束,PGA释放
创建新用户
基本创建语法于概念:
1 :要连接到Oracle数据库,就需要创建一个用户帐户
2 :每个用户都有一个默认表空间和一个临时表空间
3 :CREATE USER命令用于创建新用户

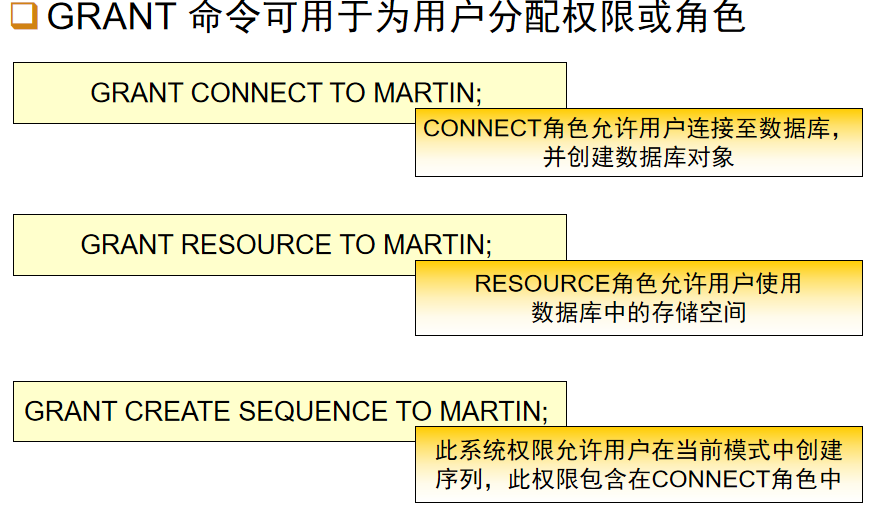
权限说明:
1 :权限指的是执行特定命令或访问数据库对象的权利
2 :权限有两种类型,系统权限和对象权限
(1)系统权限允许用户执行某些数据库操作,如创建表就是一个系统权限
(2)对象权限允许用户对数据库对象(如表、视图、序列等)执行特定操作
3 :角色是一组相关权限的组合,可以将权限授予角色,再把角色授予用户,以简化权限管理。
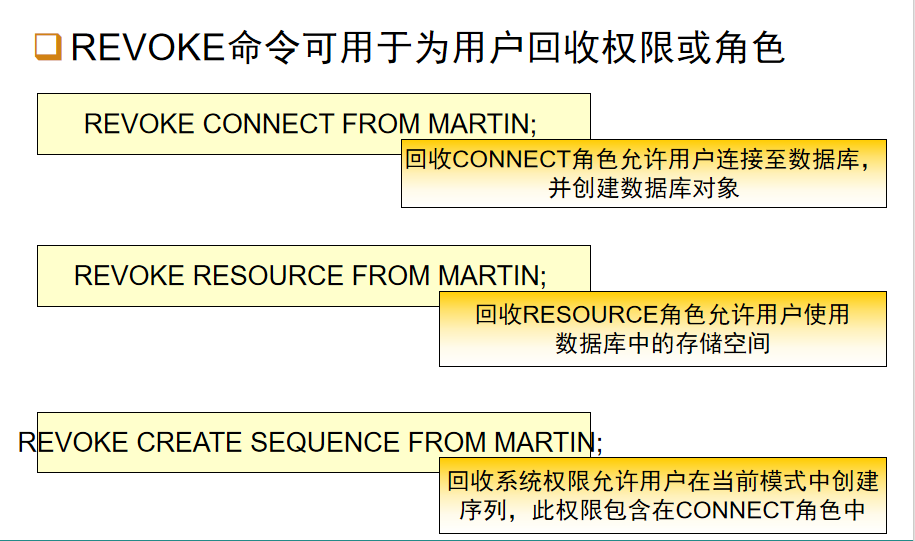
权限的相关语法:



基础总结 :
1 :Oracle 服务器由Oracle 数据库和 Oracle 实例组成
2 : Oracle 实例由系统全局区内存结构和用于管理数据库的后台进程组成
3 :Oracle 中用于访问数据库的主要查询工具有 SQLPlus、iSQLPlus 和 PL/SQLOracle
企业管理器是用于管理、诊断和调整多个数据库的工具
4 :Oracle 中的 SYSTEM 用户和 SYS 用户具有管理权限,而 SCOTT 用户只有基本的权限
5 :Oracle 服务在 Windows 注册表中注册,并由 Windows 操作系统管理
数据库表管理
完整性
数据完整性:可靠性 + 准确性 = 数据完整性
完整性包括:域完整性、实体完整性、引用完整性、自定义完整性(基本用不上了)
约束
确保输入的数据满足指定的要求,否则将拒绝相应的数据修改
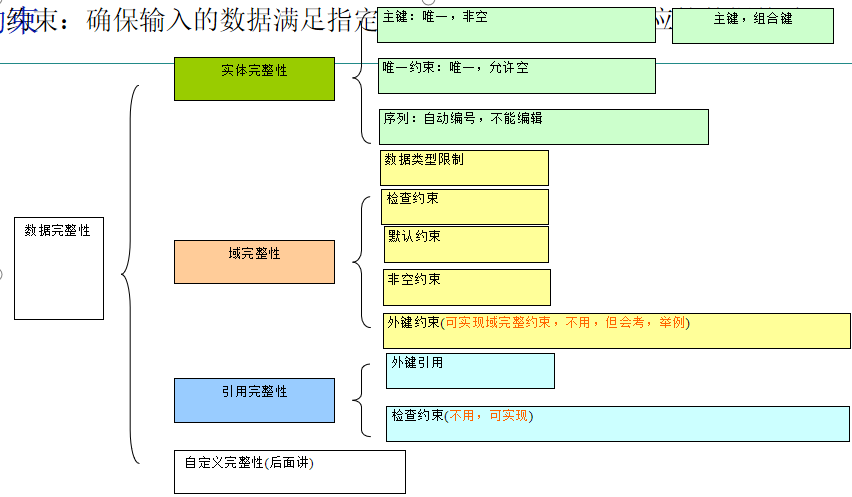
实体完整性
1 :主键: 唯一且非空(学号)
2 :组合主键 :以多个字段作为一个主键使用
3 :唯一约束 :唯一,允许一个空 (身份证号码)
4 :序列:自动编号,不能编辑
域完整性
1 :数据类型限制
2 :检查约束
检查约束 age>=10 and age<=80
3 :默认约束
我们班可能男生占绝大多数,可以通过设置默认约束设置默认值为“男”
4 :非空约束
学生姓名可以重复,但不能为空,设置非空约束
5 :外键约束
引用完整性
1 :从表的外键字段上出现的任何数据在主表的主键字段上必须得有。
2 :主表的主键字段上出现的数据在从表的外键字段中可有,可无,可重复
常用数据类型
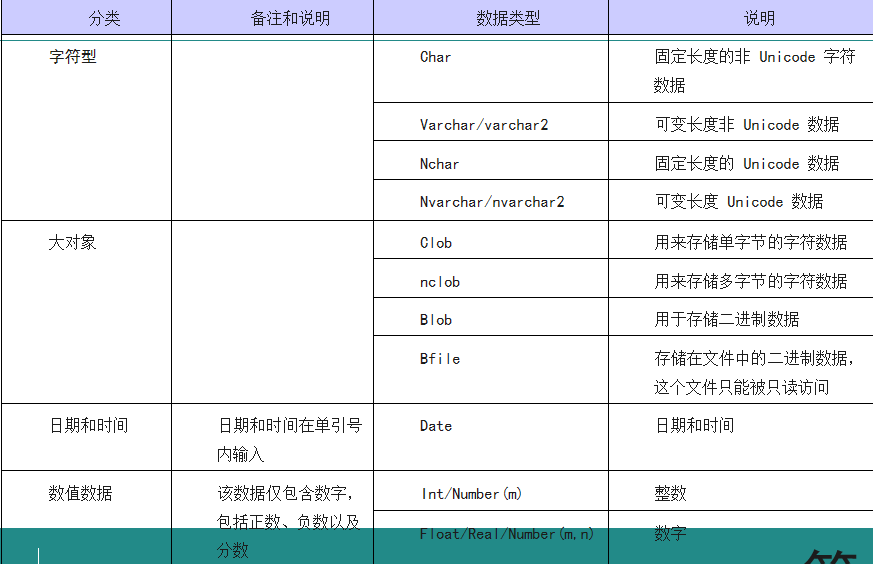
创表语法
create table tbEmp
(
eID number primary key, --职员编号
eName varchar2(20) not null, --职员姓名
eSex varchar2(2) not null --职员性别
check(esex in ('男','女')),
eAge number not null check(eage>=18), --职员年龄
eAddr varchar2(50) not null, --职员地址
eTel varchar2(30) not null, --职员电话
eEmail varchar2(30) null, --职员邮箱
eJoinTime date not null --入职时间
);
约束语法
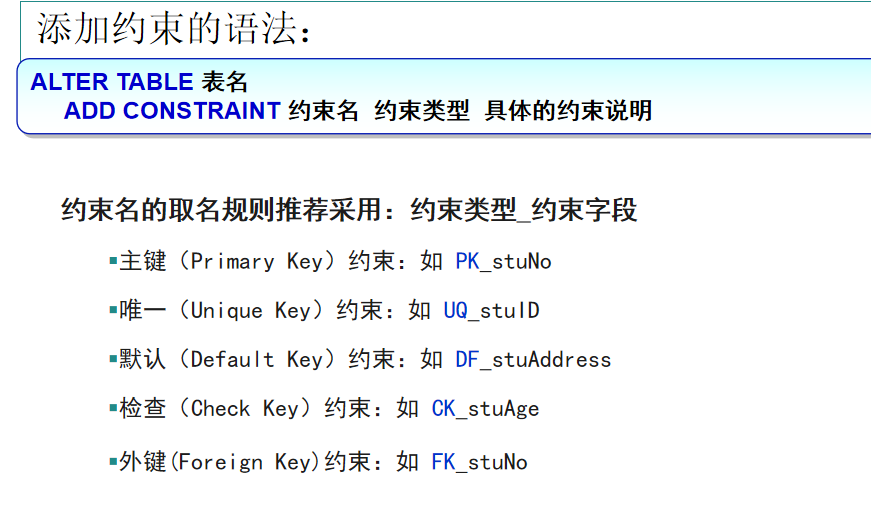
ALTER TABLE stuInfo
ADD CONSTRAINT PK_stuNo PRIMARY KEY (stuNo);
ALTER TABLE stuInfo
ADD CONSTRAINT UQ_stuID UNIQUE (stuID);
alter table stuInfo
modify(stu_address varchar2(200) default '地址不详');
ALTER TABLE stuInfo
ADD CONSTRAINT CK_stuAge
CHECK(stuAge >= 15 AND stuAge <= 40);
ALTER TABLE stuMarks
ADD CONSTRAINT FK_stuNo
FOREIGN KEY(stuNo) REFERENCES stuInfo(stuNo);
总结
1 :数据库创建表的过程是规定数据列的属性的过程,同时也是实施数据完整性(包括实体完整性、引用完整性和域完整性等)保证的过程
2 :实体完整性数据行不能存在重复,引用完整性要求子表中的相关项必须在主表中存在
3 :域完整性实现了对输入到特定列的数值的限制
4 :数据库中存在五种约束,分别是:主键约束、外键约束、检查约束、默认约束和唯一性约束
5 :创建数据库表需要:确定表的列名、数据类型、是否允许为空,还需要确定主键、必要的默认值和检查约束
6 :如果建立了主表和子表的关系,则:
——子表中的相关项目的数据,在主表中必须存在;
——主表中相关项的数据更改了,则子表对应的数据项也应当随之更改;
——在删除子表之前,不能够删除主表;
数据管理
SQL的组成 :
1 :DML(数据操作语言)
——插入、删除和修改数据库中的数据;
——INSERT、 UPDATE 、DELETE等;
2 :DCL(数据控制语言)
——用来控制存取许可、存取权限等;
——GRANT、REVOKE 等;
3 :DDL(数据定义语言)
——用来建立数据库、数据库对象和定义其列
——CREATE TABLE 、DROP TABLE 等
插入语句
insert into tbemp
(eID,ename,esex,eage,eaddr,etel,eemail,ejointime)
values
(1,'赵龙','男',25,'湖南省长沙市伍家岭江南苑9栋203号','0731-4230123','zl@163.net','5-10月-2005');
insert into tbemp
(eID,ename,esex,eage,eaddr,etel,eemail,ejointime)
values
(2,'李云','女',23,'湖南省长沙市东风路东风新村21栋502号','0731-4145268','ly@163.net','3-7月-2003');
insert into tbemp
(eID,ename,esex,eage,eaddr,etel,eemail,ejointime)
values
(3,'孙一成','男',24,'湖南省株洲市601厂宿舍15栋308号','0732-8342567','syc@163.net','2-11月-2002');
insert into tbemp
(eID,ename,esex,eage,eaddr,etel,eemail,ejointime)
values
(4,'林笑','男',27,'湖南省郴洲市人民医院20栋301号','0735-2245214','lx@163.net','5-1月-2006');
insert into tbemp
(eID,ename,esex,eage,eaddr,etel,eemail,ejointime)
values
(5,'卫晴','女',23,'湖南省长沙市望月湖12栋403号','0731-8325124','wq@163.net','5-3月-2007');
注意事项:
1:每次插入一行数据,不可能只插入半行或者几列数据,因此,插入的数据是否有效将按照整行的完整性的要求来检验;
2:每个数据值的数据类型、精度和小数位数必须与相应的列匹配;
3:如果在设计表的时候就指定了某列不允许为空,则必须插入数据;
4:插入的数据项,要求符合检查约束的要求
5:具有缺省值的列,可以使用DEFAULT(缺省)关键字来代替插入的数值
更新语句
UPDATE <表名> SET <列名 = 更新值,…> [WHERE <更新条件>]
例子:
UPDATE Students SET SSEX = 0
UPDATE Students
SET SAddress ='北京女子职业技术学校家政班'
WHERE SAddress = '北京女子职业技术学校刺绣班'
UPDATE Scores
SET Scores = Scores + 5
WHERE Scores <= 95
删除语句
DELETE FROM <表名> [WHERE <删除条件>]
TRUNCATE TABLE <表名>
TRUNCATE TABLE Students = DELETE FROM Students
总结
1 :SQL(结构化查询语言)是数据库能够识别的通用指令集
2 :数据库中的通配符经常和LIKE结合使用来进行不精确的限制
3 :WHERE用来限制条件,其后紧跟条件表达式使用
4 :UPDATE更新数据,一般都有限制条件使用
5 :DELETE删除数据时,不能删除被外键值所引用的数据行
数据查询
查询的意思:查询产生一个虚拟表,看到的是表形式显示的结果,但结果并不真正存储,每次执行查询只是现从数据表中提取数据,并按照表的形式显示出来
基本语句 :
SELECT <列名> FROM <表名> [WHERE <查询条件表达式>] [ORDER BY <排序的列名>[ASC或DESC]]
例子:
select * from tbEmp;
-- 2. 查询所有职员的姓名,电话,地址
select eName,eTel,eAddr from tbEmp;
-- 3. 查询所有女职员的详细信息
select * from tbEmp where eSex = '女';
-- 4. 查询年龄在24到26岁之间的职员的姓名,性别
select eName,eSex from tbEmp where eAge >= 24 and eAge <= 26;
-- 5. 查询家住长沙的女职员的姓名,电话,地址
select eName,eTel,eAddr from tbEmp where eSex = '女' and eAddr like '%长沙%';
-- 6. 查询李云,孙一成,林笑的电话,地址
select eTel,eAddr from tbEmp where eName in ('李云','孙一成','林笑');
-- 7. 查询郴洲和株洲的职员的姓名,性别,年龄
select eName,eSex,eAge from tbEmp where eAddr like '%株洲%' or eAddr like '%郴洲%';
-- 8. 查询家住长沙,年龄在25到28岁之间的男职员的姓名
select eName from tbEmp where eAddr like '%长沙%' and eAge >= 25 and eAge <= 28 and eSex = '男';
-- 9. 查询邮件地址为空的职员
select * from tbEmp where eEmail is null;
-- 10.查询入职时间超过两年的员工
select * from tbEmp where eJoinTime <= add_months(sysdate,-24);
-- 11.查出1月份入职的员工
select * from tbEmp where extract(month from eJoinTime) = 1;
-- 12.将所有email为163.net的邮箱改为126.com
update tbEmp set eEmail = replace(eEmail,'163.net','126.com')where eEmail like '%163.net%';
-- 13.找出年龄最小的两位长沙员工
SELECT * FROM tbEmp WHERE eAddr LIKE '%长沙%' and ROWNUM < 3 order by eAge asc ;
-- 14.查找员工信息,要求结果集表达方式为
-- 字段名:个人信息
-- 内容描述:'员工1,赵龙,今年25岁,家住湖南省长沙市伍家岭江南苑9栋203号'
SELECT '员工'||tbEmp.eID||','||tbEmp.eName||','||'今年'||eAge||'岁,家住'||tbEmp.eAddr as 个人信息 from tbEmp;
-- 15.求所有员工的年龄总和
SELECT SUM(eAge) as 全体年龄 from tbEmp;
-- 16.分别求男,女员工年龄总和
SELECT SUM(eAge) from tbEmp group by eSex;
oracle中的函数:
日期函数:
ADD_MONTHS(日期,增值):追加一个月份
SYSDATE:获得系统时间
MONTHS_BETWEEN(日期,日期):两日期相差多少月
LAST_DAY(日期):返回当月最大天数
ROUND(number,[integer])四舍五入
NEXT_DAY(日期,星期):获得某一日期后的第一个星期的值
TRUNC(date,[fmt]):舍去某一日期类型
EXTRACT(fmt from date):从当前日期提取一日期类型
字符函数:
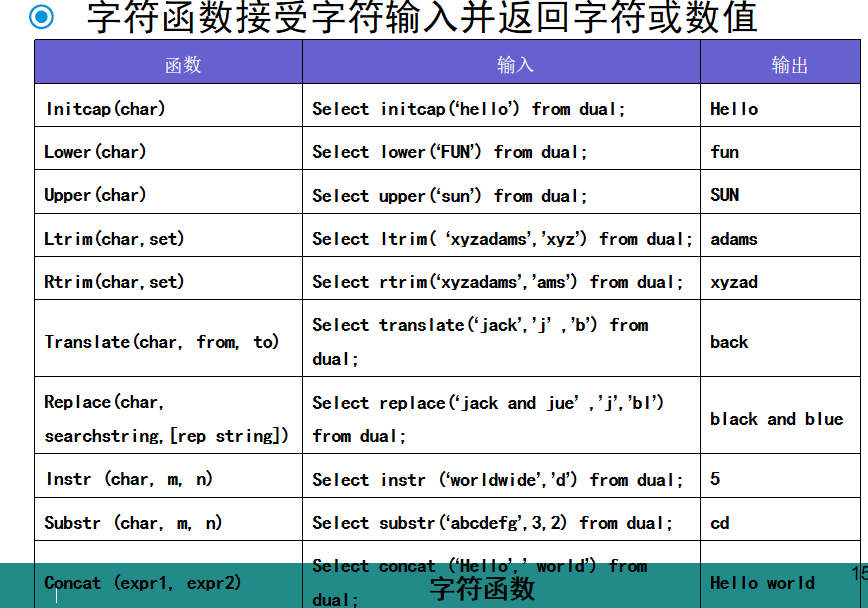
数字函数:
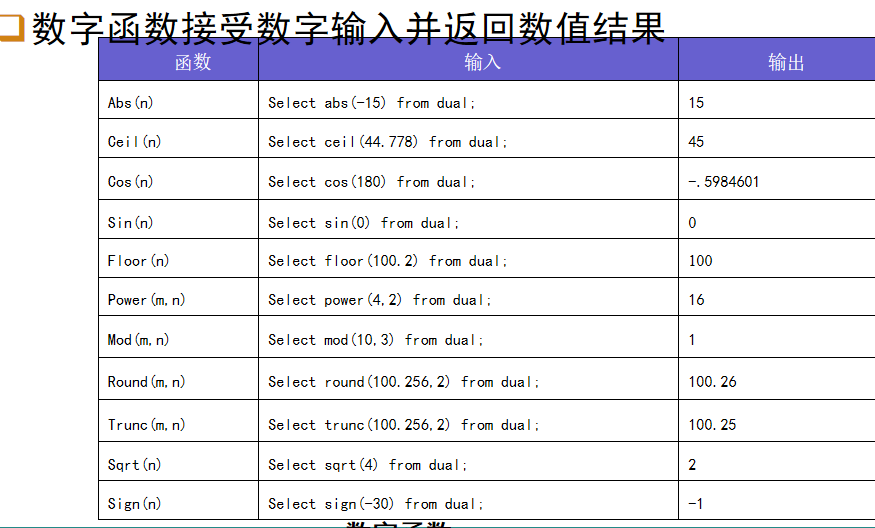
转换函数:
转换函数将值从一种数据类型转换为另一种数据类型
常用的转换函数有:TO_CHAR、TO_DATE、TO_NUMBER
例子:
SELECT TO_DATE(‘2005-12-06’ , ‘yyyy-mm-dd’)
FROM dual;
SELECT TO_NUMBER('100') FROM dual;
SELECT TO_CHAR(sysdate,'YYYY"年"fmMM"月"fmDD"日" HH24:MI:SS')
FROM dual;
SELECT TO_CHAR(itemrate,‘C99999’) FROM itemfile;
其他函数:
1 :NVL (expr1, expr2):expr1为NULL,返回expr2;不为NULL,返回expr1
2 :NVL2 (expr1, expr2, expr3) ->expr1不为NULL,返回expr2;为NULL,返回expr3。expr2和expr3类型不同的话,expr3会转换为expr2的类型
3 :NULLIF (expr1, expr2) ->相等返回NULL,不等返回expr1
SELECT itemdesc, NVL(re_level,0) FROM itemfile;
SELECT itemdesc, NVL2(re_level,re_level,max_level)
FROM itemfile;
SELECT itemdesc, NULLIF(re_level,max_level)
FROM itemfile;
模糊查询—LIKE
例子:SELECT SName AS 姓名 FROM Students WHERE SName LIKE '张%'
模糊查询—IS NULL
例子:SELECT SName As 姓名 SAddress AS 地址 FROM Students WHERE SAddress IS NULL
模糊查询—BETWEEN
例子:SELECT StudentID, Score FROM SCore WHERE Score BETWEEN 60 AND 80
模糊查询—IN
例子:SELECT SName AS 学员姓名,SAddress As 地址 FROM Students WHERE SAddress IN ('北京','广州','上海')
聚合函数:
sum,avg,max,min,count
分组查询—GROUP BY:
SELECT CourseID, AVG(Score) AS 课程平均成绩FROM ScoreGROUP BY CourseID
分组查询—HAVING:
SELECT StudentID AS 学员编号,CourseID AS 内部测试, AVG(Score) AS 内部测试平均成绩FROM ScoreGROUP BY StudentID,CourseIDHAVING COUNT(Score)>1
分组查询对比:
WHERE子句从数据源中去掉不符合其搜索条件的数据
GROUP BY子句搜集数据行到各个组中,统计函数为各个组计算统计值
HAVING子句去掉不符合其组搜索条件的各组数据行
多表联结查询:
1:内联结(INNER JOIN)
2:外联结:
左外联结 (LEFT JOIN)
右外联结 (RIGHT JOIN)
完整外联结(FULL JOIN)
3:交叉联结(CROSS JOIN)(基本用不上)
总结:
1:使用LIKE、BETWEEN、IN关键字,能够进行模糊查询 —— 条件不明确的查询
2:聚合函数能够对列生成一个单一的值,对于分析和统计通常非常有用
3:分组查询是针对表中不同的组,分类统计和输出,GROUP BY子句通常会结合聚合函数一起来使用
4:HAVING子句能够在分组的基础上,再次进行筛选
5:多个表之间通常使用联结查询
6:最常见的联结查询是内联结(INNER JOIN),通常会在相关表之间提取引用列的数据项
数据库的设计
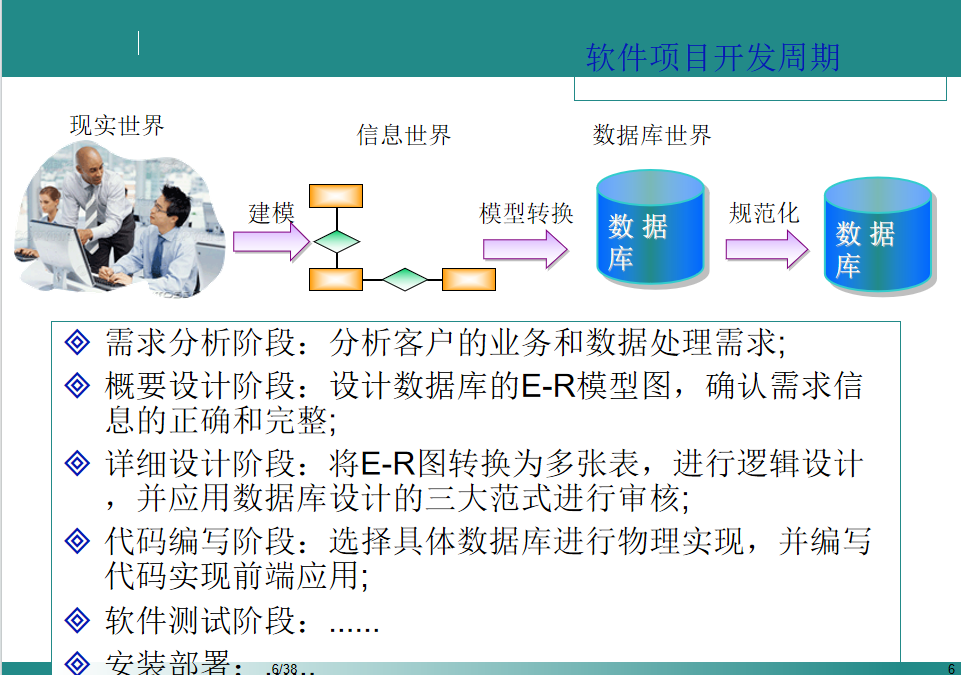
项目实际开发周期
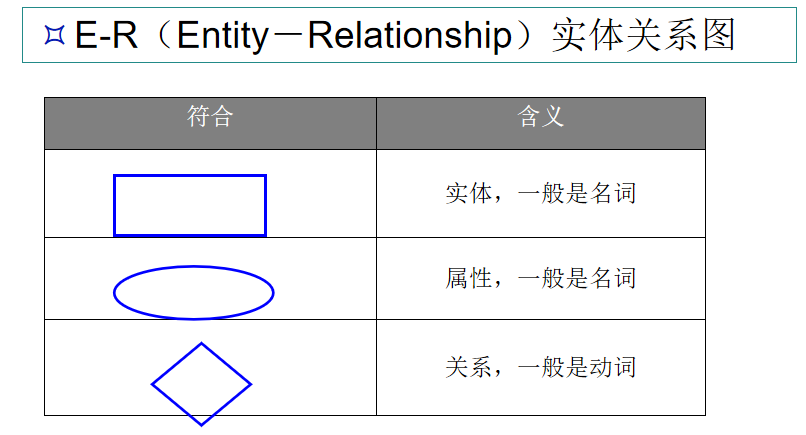
E—R图
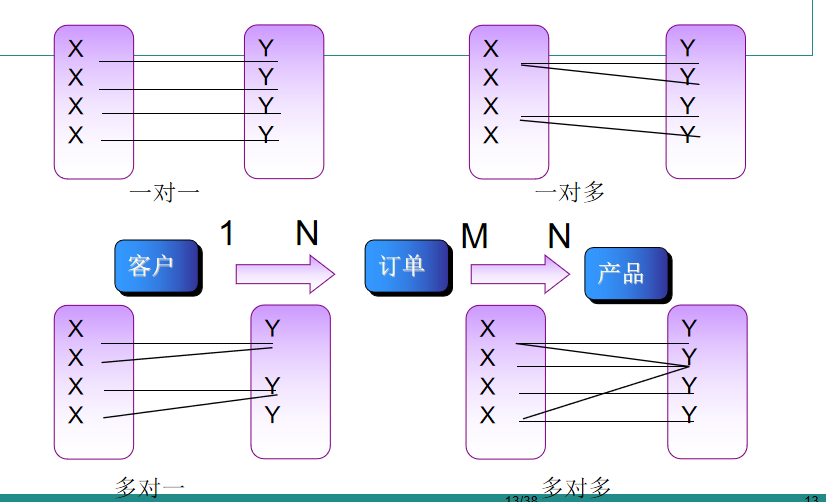
映射基数(多对多不用看)
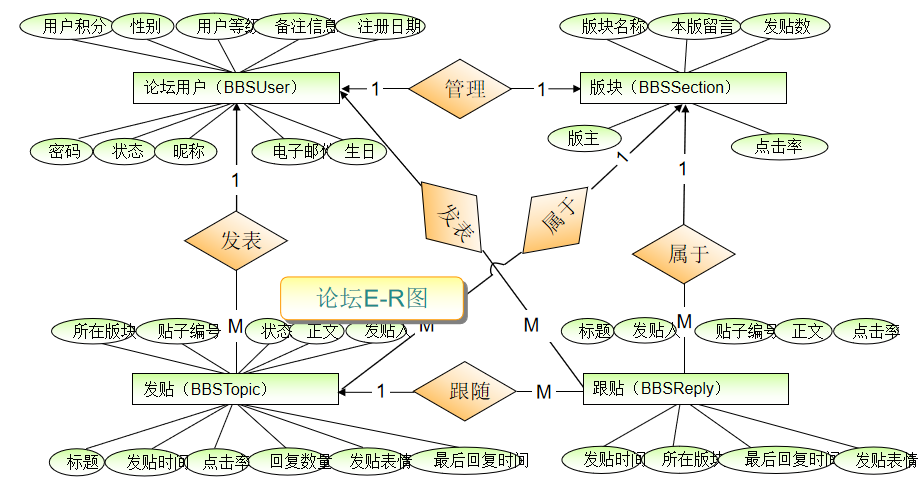
下面是一个er图的示例
E-R图转换为表
1:将各实体转换为对应的表,将各属性转换为各表对应的列
2:标识每个表的主键列,需要注意的是:没有主键的表添加ID编号列,它没有实际含义,用于做主键或外键,例如用户表中的“UID”列,版块表中添加“SID”列,发贴表和跟贴表中的“TID”列
3:在表之间建立主外键,体现实体之间的映射关系
各表之间的主键

各表之间的联系

数据规范化
1:仅有好的RDBMS并不足以避免数据冗余,必须在数据库的设计中创建好的表结构
2:Dr E.F.codd 最初定义了规范化的三个级别,范式是具有最小冗余的表结构。这些范式是
第一范式(1st NF -First Normal Fromate)
第二范式(2nd NF-Second Normal Fromate)
第三范式(3rd NF- Third Normal Fromate)
第一范式的目标是确保每列的原子性
如果每列都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式(1NF)
如果一个关系满足1NF,并且除了主键以外的其他列,都依赖与该主键,则满足第二范式(2NF)
第二范式要求每个表只描述一件事情
如果一个关系满足2NF,并且除了主键以外的其他列都不传递依赖于主键列,则满足第三范式(3NF)
总结:
在需求分析阶段,设计数据库的一般步骤为:
1:收集信息
2:标识对象
3:标识每个对象的属性
4:标识对象之间的关系
在概要设计阶段和详细设计阶段,设计数据库的步骤为:
1:绘制E-R图
2:将E-R图转换为表格
3:应用三大范式规范化表格
为了设计结构良好的数据库,需要遵守一些专门的规则,称为数据库的设计范式。
第一范式(1NF)的目标:确保每列的原子性。
第二范式(2NF)的目标:确保表中的每列,都和主键相关 。
第三范式(3NF)的目标:确保每列都和主键列直接相关,而不是间接相关 。