05.函数和递归
5. 函数和递归
inline functions ---内联函数 function template---函数模板
5.1 C++中的程序构件


function prototype---函数原型
5.1.1 函数原型
A function prototype is a declaration of a function that tells the compiler the function’s name, its return type and the types of its parameters.
参数强制转换是编译器可以将参数从一种类型隐式转换为另一种类型的一种技术。 它遵循论据提升规则。 如果一个参数是较低的数据类型,则可以将其转换为较高的数据类型,但反之则不成立。 原因是如果将一个较高的数据类型转换为较低的数据类型,则可能会丢失一些数据。
5.2 C++库头文件

macro---宏
5.3 随机数的产生
随机数的产生可以使用i=rand();
rand函数产生一个0到RAND_MAX之间的无符号整数,如果rand真的产生了一个任意整数,那么在范围内的整数的出现概率是相同的。头文件为 <cstdlib >
为了产生范围在0-5之内的随机整数,我们使用:
rand()%6;
由于要模拟骰子的点数,所以在后面+1.
C++14引入了一个新的语法特性,即数字分隔符(Digit Separators,也被称为"单下划线")。这个特性的引入,主要是为了提高代码的可读性。在处理大量数字,特别是长数字串时,数字分隔符可以帮助我们更清晰地看到数字的大小和单位。例如,我们可以将一个长整数1000000000写成1'000'000'000
rand实际上产生的是伪随机数(pseudorandom numbers),Repeatedly calling rand produces a sequence of numbers that appears to be random. However, the sequence repeats itself each time the program executes.
srand函数的头文件为:
需要一个无符号整数实参以及seeds rand函数来创造一组随机数,且每次执行产生的一组随机数都是不同的。
rand()函数和srand()函数必须配套使用
#include <iostream>
#include <iomanip>
#include <cstdlib>
using namespace std;
int main() {
unsigned int seed{0};
cout<<"enter seed: ";
cin>>seed;
srand(seed);
for(unsigned int counter{1};counter<=10;++counter){
cout<<setw(10)<<(1+rand()%6);
if(counter%5==0){
cout<<endl;
}
}
}
还可以使用时间作为种子(seed),为了不必每次都要输入seed,我们可以使用如下代码:
srand(static_cast<unsigned int>(time(0)));
time函数返回自从1970年1月1号到当前时间的秒数,返回的值类型为time_t,头文件为
5.3.1 放缩及平移随机数
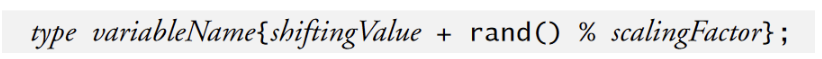
where the shiftingValue is equal to the first number in the desired range of consecutive integers and the scalingFactor is equal to the width of the desired range of consecutive integers
5.4 枚举类型(enum)
关键字enum class,后面为类型名和一组表示整数常量的标识符。例如下述代码:
enum class Status{CONTINUE,WON,LOST};
CONTINUE代表0, WON代表1, LOST代表2
一个枚举类中的标识符必须是唯一的,但是不同的枚举常数可以有相同的整数值。用户自定义类型Status的变量只能赋值在枚举中声明的三个值中的一个。
按照惯例,你应该把一个enum class 名字的第一个字母大写。
另一个流行的scoped enumeration是:
enum class Months {JAN = 1, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC};
第一个值被设置为1,剩下的值就会从1开始递增,任何一个枚举常数都可以在枚举定义中被赋予一个整数值,并且后续的枚举常数每个都比列表中的前一个常数高一个值1,直到下一个显式设置。
标识符表示的默认为整数(int),但是也可以指定不同的类型。
enum class Status : unsigned int {CONTINUE, WON, LOST};
5.5 C++11中的随机数
使用rand函数,不具备很好的统计特性,仍然可以被预测到,在C++11中,引入了头文件<random>
在本节中,我们将使用默认的随机数生成引擎- -default_random_engine和均匀分布的uniform_int_distribution,将伪随机整数均匀分布在指定的取值范围内。默认范围是从0到你的平台上的一个int的最大值。
class template---类模板
#include <iostream>
#include <iomanip>
#include <random>
#include <ctime>
using namespace std;
int main() {
default_random_engine engine{static_cast<unsigned int>(time(nullptr))};
uniform_int_distribution<unsigned int> randomInt{1, 6};
for(unsigned int counter{1};counter<=10;++counter){
cout<<setw(10)<<randomInt(engine);
if(counter%5==0){
cout<<endl;
}
}
}
5.6 作用域规则
当块是嵌套的,并且外块中的标识符与内块中的标识符具有相同的名字时,外块中的标识符被"隐藏",直到内块终止- -内块"看到"自己的局部变量的值而不是封闭块的相同命名变量的值。
局部变量也可以被声明为静态的。这样的变量也有块范围,但与其他局部变量不同的是,一个静态的局部变量在函数返回到它的调用者时保留了它的值。下次调用该函数时,静态局部变量包含该函数上次执行完毕时的值。
所有数值类型的静态局部变量默认初始化为零。下面的语句声明静态局部变量计数,并将其初始化为0:
static unsigned int count;
An identifier declared outside any function or class has global namespace scope.
全局变量是通过在任何类或函数定义之外放置变量声明来创建的。这些变量在程序执行的整个过程中保持其值。
将变量声明为全局而非局部,当一个不需要访问变量的函数意外或恶意修改变量时,就会出现意想不到的副作用。这是最小特权原则的另一个例子- -除了真正的全局资源,如cin和cout,全局变量应该避免。一般来说,变量应该在其需要访问的最窄范围内进行声明。仅在特定函数中使用的变量应声明为该函数中的局部变量而不是全局变量。
函数原型中的参数,其作用域始于左括号,终于右括号
double area(double radius);//radius的作用域仅在于括号内,不能用于程序正文以及其他地方
类的成员具有类作用域,其范围包括类体和非内联成员函数的函数体。
如果在类作用域以外访问类的成员,要通过类名(访问静态成员),或者该类的对象名、对象引用、对象指针(访问非静态成员)。
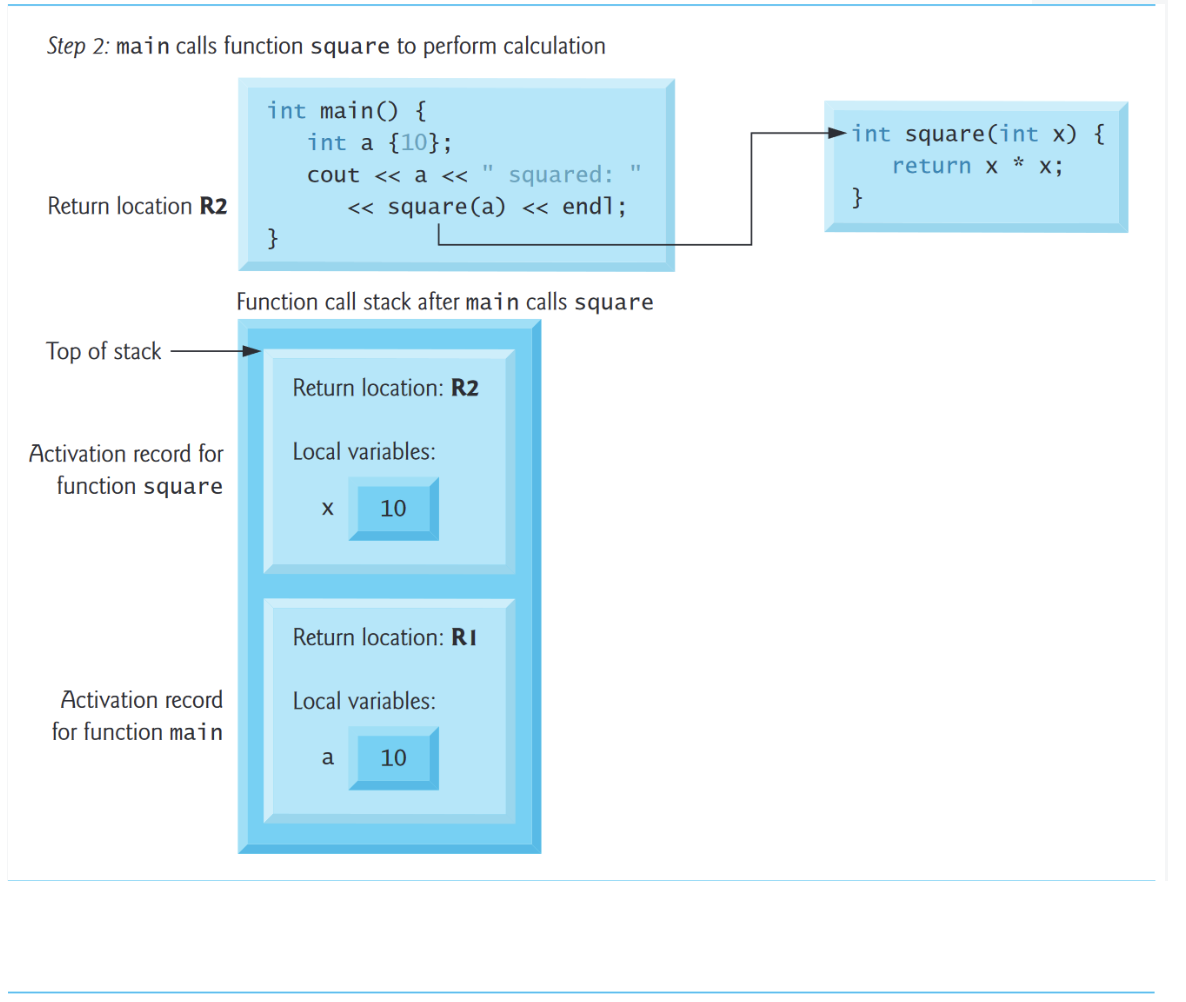
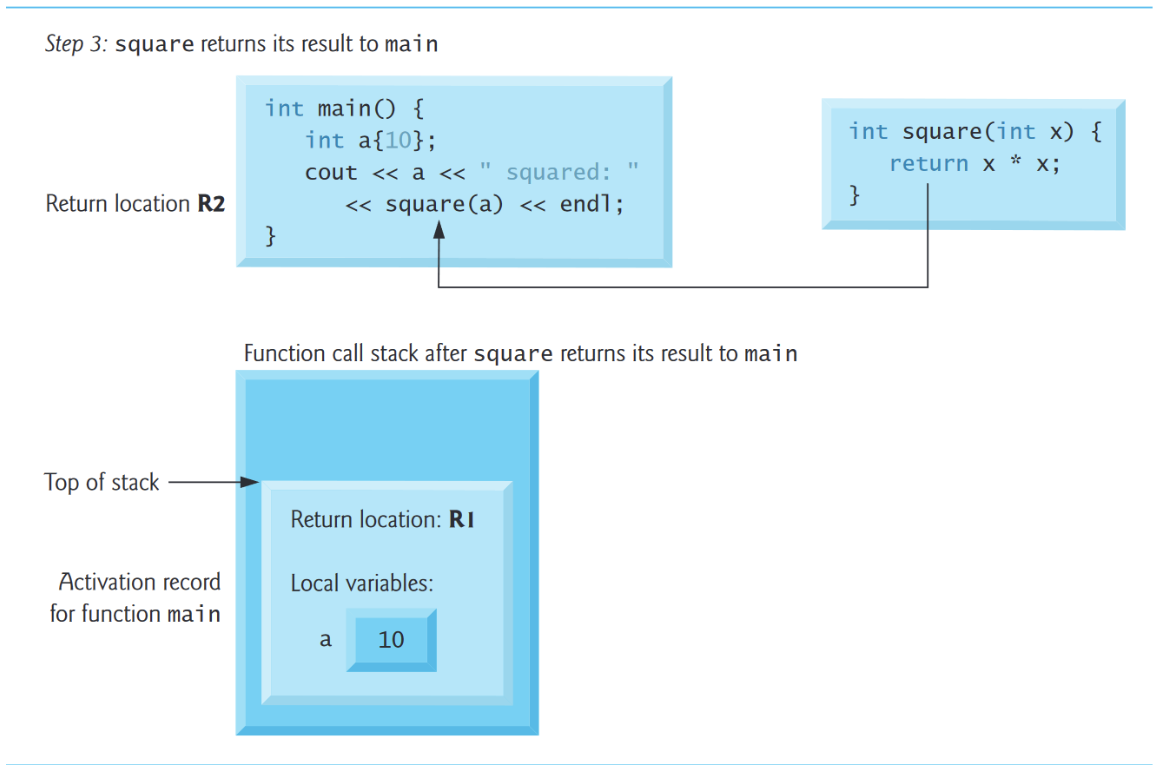
5.7 函数调用栈和激活记录
5.7.1 栈
pushing---进栈 popping---出栈
栈是后人先出结构(last-in, first-out (LIFO) data structures),即最后一个进栈的会最先出栈。
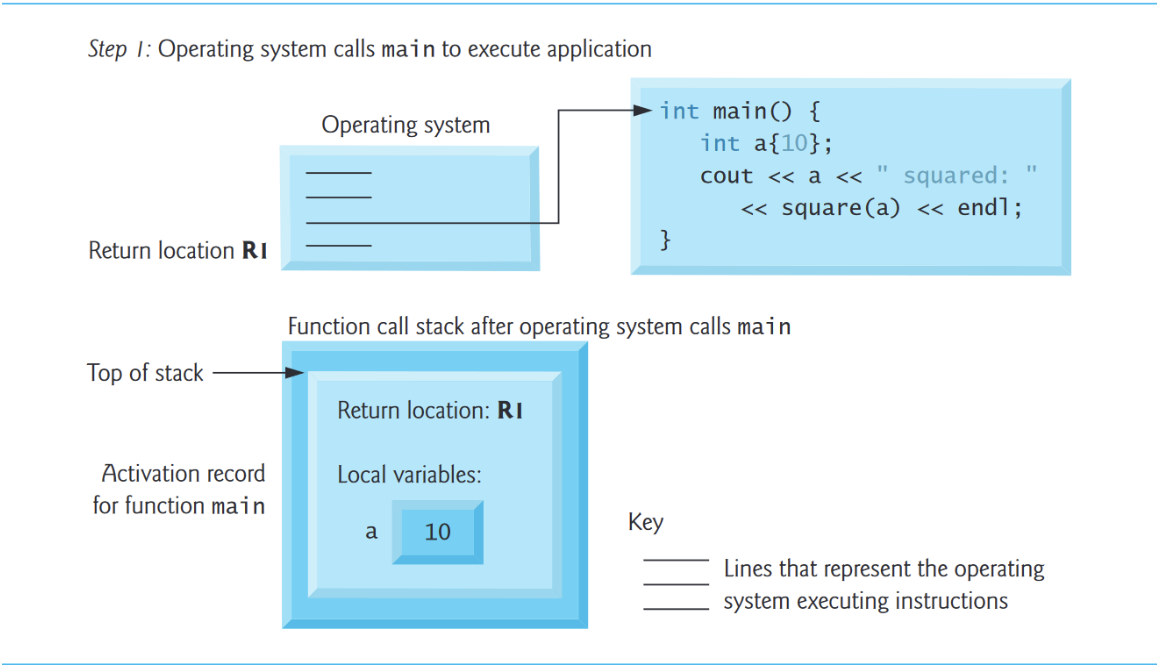
函数调用栈(function-call stack),有时也称为程序执行栈,和数据结构意义上的“栈”不同。
栈帧(Stack Frames)
每次函数调用其他函数,一条记录就会放入栈中,这条记录,就叫做栈帧或者活动记录(activation record),包含被调用函数为了返回调用函数所需要的返回地址。如果被调用的函数返回而不是在返回之前调用另一个函数,则弹出函数调用的堆栈帧,控制转移到弹出堆栈帧中的返回地址。If the called function returns instead of calling another function before returning, the stack frame for the function call is popped, and control transfers to the return address in the popped stack frame.
调用栈的美妙之处在于,每个被调用的函数总是在调用栈的顶端找到它需要返回给它的调用者的信息。并且,如果一个函数对另一个函数进行了调用,新函数调用的栈帧就被简单地推到了调用栈上。这样,新被调用函数返回其调用者所需的返回地址就位于栈的顶端。
函数在执行过程中需要存在非静态的局部变量。如果函数调用其他函数,它们需要保持活动状态。但是当一个被调用函数返回到它的调用者时,被调用函数的非静态局部变量需要"离开"。被调用函数的堆栈框架是为被调用函数的非静态局部变量预留内存的绝佳场所。只要被调用的函数是活动的,该栈帧就存在。当该函数返回而不再需要它的非静态局部变量时,它的堆栈框架从堆栈中弹出,并且这些非静态局部变量不再存在。
stack overflow(栈溢出)
#include <iostream>
using namespace std;
int square(int);
int main(){
int a{10};
cout << a << " squared: " <<square(a) << endl;
}
int square(int x){
return x*x;
}
5.8 内联函数(inline functions)
从软件工程的观点来看,将程序作为一组函数来实现是很好的,但是函数调用涉及执行时间开销。C++提供内联函数来帮助减少函数调用开销。
将限定符置于函数定义中函数的返回类型之前,建议编译器在函数调用的每个地方(适当的时候)生成函数体代码的副本,以避免函数调用。这往往会使程序变大。编译器可以忽略内联限定符,一般对除最小函数外的所有函数都这样做。可重复使用的内联函数通常放置在头文件中,因此它们的定义可以包含在每个使用它们的源文件中。
如果一个函数是内联的,那么在编译时,编译器会把该函数的代码副本放置在每个调用该函数的地方。对内联函数进行任何修改,都需要重新编译函数的所有客户端,因为编译器需要重新更换一次所有的代码,否则将会继续使用旧的函数。如果想把一个函数定义为内联函数,则需要在函数名前面放置关键字 inline,在调用函数之前需要对函数进行定义。
内联函数的声明和定义一般不分开(也可以分开,具体参见如下链接)c++ - Is possible to separate declaration and definition of inline functions? - Stack Overflow
对内联函数不能进行异常接口说明
内联函数的定义必须出现在内联函数第一次被调用之前。
如果已定义的函数多于一行,编译器会忽略 inline 限定符。
inline只适合函数体内代码简单的函数使用,不能包含复杂的结构控制语句例如while、switch,并且内联函数本身不能是直接递归函数(自己内部还调用自己的函数)。
以下情况不宜使用内联:
(1)如果函数体内的代码比较长,使用内联将导致内存消耗代价较高。
(2)如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。
(3)内联函数不能递归。
#include <iostream>
using namespace std;
inline double cube(const double side){
return side*side*side;
}
int main(){
double sideValue;
cout<<"Enter the side length of your cube: ";
cin >> sideValue;
cout<<"Volume of cube with side "
<<sideValue<<" is "<<cube(sideValue)<<endl;
}
当函数在类的声明中实现,它自动成为内联函数。
class A{
public:
A()=default;
double f1(){
//do something
}
double f2();
};
double A::f2(){
//do something
}
//f1就变成了内联函数
//f2不是内联函数
5.9 函数默认参数
某些函数有这样一种形参, 在函数的很多次调用中它们都被赋予一个相同的值, 我们把这个反复出现的值称为函数的默认实参。
当程序在函数调用时,省略形参的默认实参,编译器会重写函数调用并向那个实参插入默认值。
#include <iostream>
using namespace std;
unsigned int boxVolume(unsigned int length=1,unsigned int width=1,unsigned int height=1);
int main() {
cout<<"The default box volume is: "<<boxVolume();
cout<<"\n\nThe volume of a box with length 10,\n"
<<"width 1 and height 1 is: "<<boxVolume(10);
cout<<"\n\nThe volume of a box with length 10,\n"
<<"width 5 and height 2 is: "<<boxVolume(10,5,2)<<endl;
}
unsigned int boxVolume(unsigned int length,unsigned int width,unsigned int height){
return length*width*height;
}
在上述代码中,函数的原型指明三个形参都有默认值1。第一次调用boxVolum函数,没有指定实参,所以使用的是三个默认值1。第二次调用只传递了一个length实参,所以width和height仍然使用的默认实参1。最后一次调用,传入了三个实参,就不要默认实参了。
任何显式传递给函数的实参均从左至右赋值给函数的形参。
默认实参必须是函数形参列表最右边的实参。当调用的函数有两个或者多个默认实参,如果一个遗漏的实参不是最右边的实参,那么所有的实参都必须被省略。默认实参必须在函数名称首次出现时指明---典型的,在函数原型中。如果函数原型遗漏了,那么默认实参应该在函数头中指明。默认值可以是任意表达式,包括常量,全局变量或者函数调用。默认实参也可以在内联函数中使用。
定义时应当注意:参数列表中默认值参数应后置
void t1(int x,int y=0,int z);//错误
void t2(int x-0,inty=0,int z);//错误
void t3(int x,int y=0,int z=0);//正确
void t4(int x=0,int y=0;int z=0);//正确
调用时应当注意:参数列表中实参应前置
t3(1, ,7);//错误
t4( , ,6);//错误
t3(1);//正确,y,z使用默认值
t4(1,2);//正确,z使用默认值
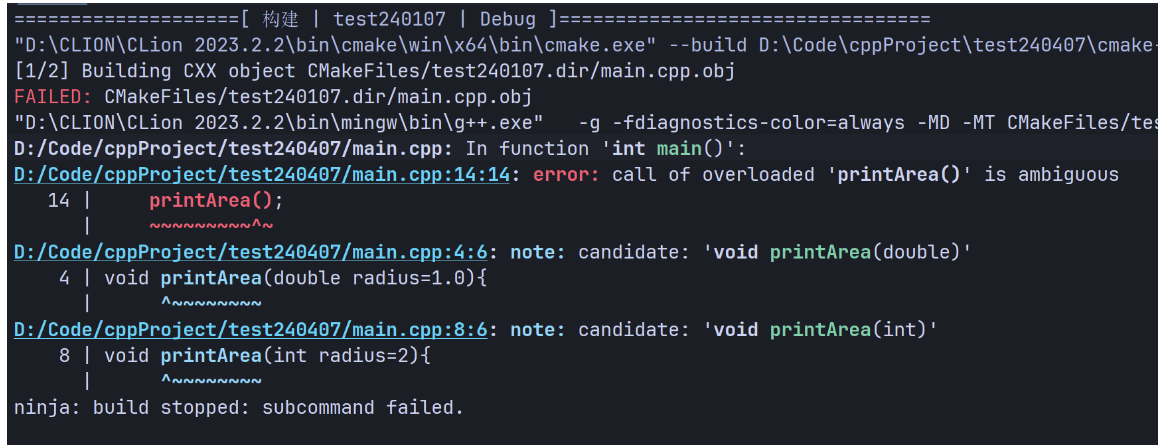
函数重载时,不允许重定义默认参数。
#include <iostream>
using namespace std;
void printArea(double radius=1.0){
cout<<radius*2<<endl;
}
void printArea(int radius=2){
cout<<radius*radius<<endl;
}
int main() {
printArea();
printArea(4);
return 0;
}
5.10 一元作用域解析运算符(:😃
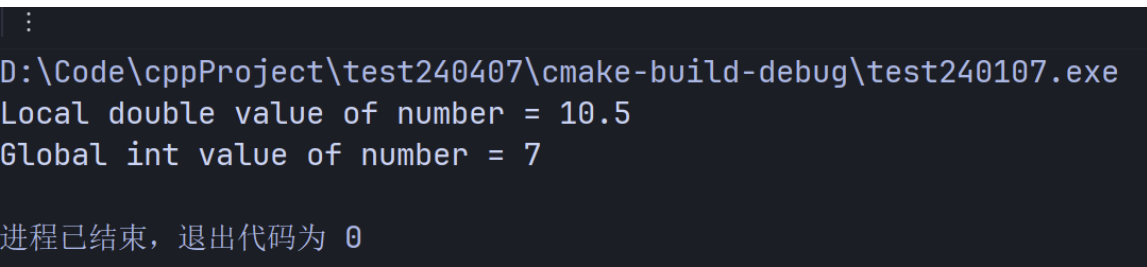
当一个同名的局部变量在作用域时,C++提供一元作用域解析运算符(::)来访问全局变量。 一元作用域解析运算符不能用于访问外部块中同名的局部变量。如果一个全局变量的名字与一个局部变量的名字在范围上不相同,则可以直接访问一个全局变量,而不需要一元作用域解析运算符。
#include <iostream>
using namespace std;
int number{7};
int main() {
double number{10.5};
cout << "Local double value of number = "
<<number
<< "\nGlobal int value of number = "
<<::number<<endl;
}
第二个作用是在类外定义函数,例如:
#include<iostream>
using namespace std;
class A
{
public:
// Only declaration
void fun();
};
// Definition outside class using ::
void A::fun()
{
cout << "fun() called";
}
int main()
{
A a;
a.fun();
return 0;
}
第三个作用是访问类的静态变量,参照本文档的8.14节
第四个作用是:如果有多个继承:如果两个祖先类中存在相同的变量名,则可以使用作用域运算符进行区分。例如:
// Use of scope resolution operator in multiple inheritance.
#include<iostream>
using namespace std;
class A
{
protected:
int x;
public:
A() { x = 10; }
};
class B
{
protected:
int x;
public:
B() { x = 20; }
};
class C: public A, public B
{
public:
void fun()
{
cout << "A's x is " << A::x;
cout << "\nB's x is " << B::x;
}
};
int main()
{
C c;
c.fun();
return 0;
}
第五个作用是:对于命名空间:如果两个命名空间中都存在一个具有相同名称的类,则可以将名称空间名称与作用域解析运算符一起使用,以引用该类而不会发生任何冲突
#include<iostream>
int main(){
std::cout << "Hello" << std::endl;
}
在这里,cout和endl属于std命名空间。具体参照本文的8.14.5
第六个作用是:在另一个类中引用一个类:如果另一个类中存在一个类,我们可以使用嵌套类使用作用域运算符来引用嵌套的类。
#include<iostream>
using namespace std;
class outside
{
public:
int x;
class inside
{
public:
int x;
static int y;
int foo();
};
};
int outside::inside::y = 5;
int main(){
outside A;
outside::inside B;
}
5.11 重载函数(Overloading Functions)
C++允许多个相同名称的函数被定义,只要它们具有不同的特征。这就叫做函数重载。
C++通过验证引用的实参的数量、数据类型和顺序来选择合适的函数调用。函数重载被用来生成多个执行相似任务、具有相同名字的函数,但数据类型不同。
#include <iostream>
using namespace std;
int square(int x){
cout<<"square of integer "<<x<<"is";
return x*x;
}
double square(double y){
cout<<"square of double "<<y<<"is";
return y*y;
}
int main(){
cout<<square(7);
cout<<endl;
cout<<square(7.5);
cout<<endl;
}
重载函数通过他们的特征来区分,特征(signatures)是函数的名字和形参类型(按顺序)的结合。编译器需要为C++中的所有函数,在符号表中生成唯一的标识符,来区分不同的函数。而对于同名不同参的函数,编译器在进行name mangling操作时,会通过函数名和其参数类型生成唯一标识符,来支持函数重载,以实现类型安全的联结属性(type-safe linkage)。类型安全的联结属性保证了合适的重载函数被调用,并且实参的类型和形参的类型一致。
注意:name mangling 后得到的函数标识符与返回值类型是无关的,因此函数重载与返回值类型无关。
- 函数的参数个数、参数类型、参数顺序不同三者中满足其中一个,就是函数重载了
- 如果只有函数返回值不同,不是函数重载;返回值不同,参数也不同的时候,可以作为函数重载
函数的重载的规则:
- 函数名称必须相同。
- 参数列表必须不同(个数不同、类型不同、参数排列顺序不同等)。
- 函数的返回类型可以相同也可以不相同。
- 仅仅返回类型不同不足以成为函数的重载。
- 如果重载函数有默认参数,调用函数时,可能导致匹配失败
- const不能作为函数重载的特征
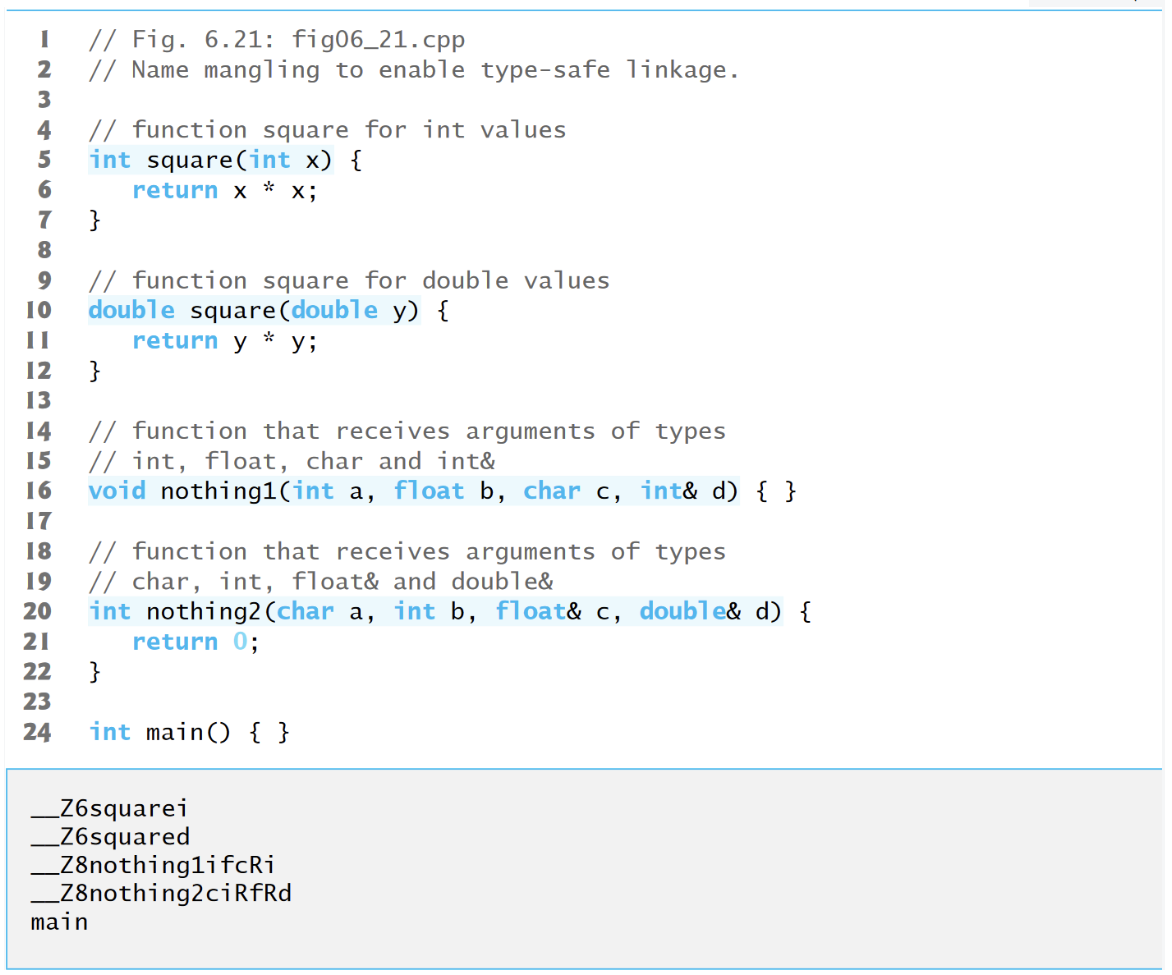
上述代码就显示了编译器以汇编语言生成的函数名(mangled function names)。对于GNU C++ 每个mangled name(main函数除外)都以两个下划线开始,后面跟字母Z、一个数字和函数的名字,Z后面的数字指明函数名包括多少个字符。例如square函数的形参为int类型,就在square后加i。在nothing1中,形参类型分别为int、float、char和int & ,所以nothing后加ifcRi。
重载函数可以有不同的返回类型,但是如果返回类型不同,他们必须有不同的形参列表。
5.12 函数模板(function templates)
重载函数通常用于在不同数据类型上执行涉及不同程序逻辑的类似操作。如果每种数据类型的程序逻辑和操作完全相同,使用函数模板可以更紧凑、方便地执行重载操作。 编写了以一个函数的模板定义,C + +根据对该函数调用提供的参数类型,自动生成单独的函数模板特殊化(function template specializations),以妥善处理每种类型的调用。因此,定义一个函数模板本质上是定义了一整族重载函数。
C++提供了模板(template)编程的概念。所谓模板,实际上是建立一个通用函数或类,其类内部的类型和函数的形参类型不具体指定,用一个虚拟的类型来代表。这种通用的方式称为模板。
在 C++ 中,模板分为函数模板和类模板两种。函数模板是用于生成函数的,类模板则是用于生成类的。
函数模板的写法如下:
template <typename 类型参数1, typename 类型参数2, ...>
返回值类型 模板名(形参表)
{
函数体
}
函数模板看上去就像一个函数。
例如对于交换多种类型的值的函数,可以编写函数模板如下:
template <typename T>
void Swap(T & x, T & y)
{
T tmp = x;
x = y;
y = tmp;
}
上述代码形参列表中的形参不能改成不带引用的形式:
void Swap(T x,T y)
上述形式的代码不能实现两个数值的交换,因为在将实参传递给形参后,是形参进行的数值交换,main函数体内的实参并没有进行数值交换。所以要使用引用。

同一个类型参数只能替换为同一种类型。编译器在编译到调用函数模板的语句时,会根据实参的类型判断该如何替换模板中的类型参数。
所有的模板定义都以关键词template开始(第一行),后面跟模板形参列表。每个模板形参列表内的形参都在前面加上关键词typename或者class(在此种情形下,两者等价)。template parameters有三种类型:
1)Type parameters(类型参数):
2)Nontype parameters(非类型参数):
3)template template parameters(双重模板参数)
类型参数是基本类型或用户自定义类型的占位符。占位符就是先占住一个固定的位置,等着你再往里面添加内容的符号,广泛用于计算机中各类文档的编辑。格式占位符(%)是在C/C++语言中格式输入函数,如 scanf、printf 等函数中使用。其意义就是起到格式占位的意思,表示在该位置有输入或者输出。
这些占位符,例如T,被用来指定函数形参的类型(例如第二行)和指定函数的返回类型(第二行),还有在函数体内声明变量(第三行)。一个函数模板的定义就像函数的定义一样,只是使用类型参数作为实际数据类型的占位符。
template<typename T>
T maximum(T value1,T value2,T value3){
T maximumValue{value1};
if(value2>maximumValue){
maximumValue=value2;
}
if(value3>maximumValue){
maximumValue=value3;
}
return maximumValue;
}
函数模板在第一行声明了单个类型参数T作为函数maximum待测数据类型的占位符。对于特定的模板定义,类型参数的名称必须在模板形参列表中唯一。当编译器在程序源代码中检测到maximum调用时,在整个模板定义中将maximum调用中的实参类型替换成T,C++创建了一个完整的函数,用于确定指定类型的3个值中的最大值- -这3个值必须具有相同的类型,因为在本例中我们只使用了一个类型参数。 然后对新创建的函数进行编译- -模板是代码生成的一种手段。
#include <iostream>
#include "maximum.h"
using namespace std;
int main(){
cout<<"input three integer values: ";
int int1,int2,int3;
cin>>int1>>int2>int3;
cout<<"the maximum integer value is: "
<<maximum(int1,int2,int3);
cout << "\n\nInput three double values: ";
double double1, double2, double3;
cin >> double1 >> double2 >> double3;
cout << "The maximum double value is: "
<<maximum(double1, double2, double3);
cout<<"\n\nInput three characters: ";
char char1, char2, char3;
cin >> char1 >> char2 >> char3;
cout << "The maximum character value is: "
<< maximum(char1, char2, char3)<< endl;
}
为type int创建的函数模板特殊化将T的每个出现替换为int如下:

函数模板不是函数,写了函数模板,但不在任何地方使用它(也不显式实例化),则编译器不会为该函数模板生成任何代码。函数模板实例化分为隐式实例化和显式实例化。
5.12.1 隐式实例化
仍以 swap 为例,我们在main 中调用 swap(a,b)时,就发生了隐式实例化。当函数模板被调用,且在之前没有显式实例化时,即发生函数模板的隐式实例化。如果模板实参能从调用的语境中推导,则不需要提供。效率较低。
//template2.cpp #include
template void print(const T &r) {
std::cout << r << std::endl;
}
int main() {
// 隐式实例化print(int) print(1);
// 实例化 print(char) print<>('c');
// 仍然是隐式实例化,我们希望编译器生成print(double) print(1);
return 0;
}
5.13递归(recursion)
对于一些问题,函数调用自身是有用的。递归函数是一个可以直接或间接调用自身的函数(通过另一个函数)。C++标准文件指出,在程序中不应该调用main函数,也不应该递归调用main函数。它的唯一目的是作为程序执行的起点。该函数只知道如何求解最简单的情况(simplest case),或所谓的基本情况(base case)。如果以base case调用该函数,该函数返回一个结果。如果函数被更复杂的问题调用,它通常将问题分为两个概念部分- -函数知道如何做的部分和它不知道如何做的部分。为了使递归可行,后一部分问题必须与原问题相似,不过是略微简单或更小的版本。这个新问题看起来像原来的问题,所以函数调用自身的一个副本来工作在更小的问题上- -这被称为递归调用,也被称为递归步骤。递归步骤通常包括关键字return,因为它的结果会与函数知道如何解决的部分问题相结合,形成结果传回原调用者,可能是main。
递归步骤在执行时,对函数的原始调用仍然是"开放的",即还没有执行完毕。递归步骤可以导致更多的递归调用,因为函数不断地将每个新的子问题划分为两个概念部分。为了使递归最终终止,每次函数调用自身与原问题稍微简单的版本,这个越来越小的问题序列最终必须收敛于base case。此时,函数识别出base case并返回一个结果到函数的前一个副本,然后一系列的返回沿着这个行进行,直到原始的调用最终返回最终的结果给main。
5.13.1阶乘
#include <iostream>
#include <iomanip>
using namespace std;
unsigned long factorial(unsigned long);
int main() {
for(unsigned int counter{0};counter<=10;++counter){
cout<<setw(2)<<counter<<"!="<<factorial(counter)<<endl;
}
}
unsigned long factorial(unsigned long number){
if(number<=1){
return 1;
}
else{
return number* factorial(number-1);
}
}
factorial函数的形参类型为unsigned long,返回结果的类型为unsigne long,这是unsigned long int的简写。C++标准规定unsigned long int 的长度至少要和int一样。一般的,unsigned long int在计算机内存储为四个字节。
5.14 使用递归的例子:斐波那契数列
C++只规定了4种操作符的求值顺序--&&,||,逗号(,)和(?:)。
5.15 递归VS.迭代
1.迭代和递归都是基于一个控制语句:迭代使用一个迭代语句;递归使用了一个选择语句。
2.迭代和递归都涉及迭代:迭代显式地使用一个迭代语句;递归通过重复的函数调用实现迭代。
3.迭代和递归各自涉及一个终止测试:当循环继续条件失败时,迭代终止;递归在识别base case时终止。
4.counter控制的迭代和递归每次逐渐接近终止:迭代修改counter,直到counter假设一个值使得循环连续条件失败;递归产生原始问题的更简单的版本,直到达到base case。
5.迭代和递归都可以无限地发生:如果循环延续性测试从未变得错误,则随着迭代的进行会出现一个无限的循环;如果递归步骤在每次递归调用过程中没有以收敛于base case的方式减少问题,则会发生无限递归。
#include <iostream>
#include <iomanip>
using namespace std;
unsigned long factorial(unsigned int);
int main() {
for(unsigned int counter{0};counter<=10;++counter){
cout<<setw(2)<<counter<<"!="<<factorial(counter)
<<endl;
}
}
unsigned long factorial(unsigned int number){
unsigned long result{1};
for(unsigned int i{number};i>=1;--i){
result*=i;
}
return result;
}
上述代码使用迭代的方法实现了斐波那契数列。
5.15.1递归的负面效果
递归具有负面效应。它反复调用函数的机制,进而调用函数的开销。这在处理器时间和内存空间上都可能是昂贵的。每一次递归调用都会导致函数变量的另一个副本被创建;这会消耗相当大的内存。迭代通常发生在函数内部,因此省略了重复函数调用和额外内存分配的开销。
仍然选择递归的原因是任何可以递归求解的问题也可以迭代求解(非递归)。当递归方法更自然地反映问题并产生更易于理解和调试的程序时,通常选择递归方法。选择递归解的另一个原因是,当递归为解时,迭代解可能不明显。
5.16 round函数
使用round函数解决四舍五入问题比较简单。
在C++中,round()函数是标准库 中的一个函数,用于对浮点数进行四舍五入。
函数原型为:
double round(double x);
参数x是一个双精度浮点数。
round()函数将返回最接近参数x的整数。如果x正好在两个整数中间,则向远离零的整数方向取整。例如:
#include <iostream>
#include <cmath>
int main() {
double num1 = 2.5;
double num2 = 2.3;
std::cout << "round(2.3) is: " << round(num1) << std::endl; // 输出 "round(2.3) is: 2"
std::cout << "round(2.3) is: " << round(num2) << std::endl; // 输出 "round(-2.3) is: -2"
return 0;
}

5.17 函数的参数
1.在函数被调用时才分配形参的存储单元
2.实参可以是常量、变量或表达式、
3.实参类型必须与形参相符或可以隐式转换为形参类型
4.值传递是传递参数值,即单向传递
5.引用传递可以实现双向传递
6.常引用(const)作参数可以保障实参数据的安全
当函数执行完毕,在函数体内定义的变量,全部都被释放了。引用在定义时必须初始化,但是在函数的形参中使用引用并不会进行初始化。这是因为引用在定义时必须初始化,是在为引用分配内存时,必须进行初始化,但函数的形参,系统并不会为他分配内存,所以就不需要初始化。
5.17.1 可变数量形参
使用模板类initializer_list
void log_info(initializer_list<string> lst) {
for(auto &info: lst){
cout<<info<<' ';
}
cout<<endl;
}
log_info({"hello","world","!"});
5.18 对象作为函数参数和返回值
5.18.1 作为参数
对象作为函数参数,可以按值传递,也可以按引用传递。
//按值传递
void print(Circle c){
//do something
}
int main(){
Circle myCircle{5.0};
print(myCircle);
}
//按值传递
void print(Circle& c){
//do something
}
int main(){
Circle myCircle{5.0};
print(myCircle);
}
//按值传递
void print(Circle* c){
//do something
}
int main(){
Circle myCircle{5.0};
print(&myCircle);
}
5.18.2 作为函数返回值
形式如下:
Object f(函数形参){
//do something
return Object(args);
}
// main(){
Object o=f;
}