Requsets库入门篇
一.Requests库的安装
打开命令窗口执行命令 : pip install requests
二.Requests主要方法
1.这里requests库的请求方法有很多下面我只介绍我常用的两种方法
| requests.get() | 获取HTML网页的主要方法,对应HTTP的GET |
| requests.post() | 向HTML网页提交POST请求的方法,对应HTTP的POST |
2.带可选参数的的请求方法
requests.request(method, url, params=params, **kwargs)
method:请求方法对应get和post等方法
url:获取的页面的url连接
**kwargs:可选的参数:
params:传入的是路由对应参数,以字典的形式键与值对应传入,以作为url中的参数
headers:请求头以字典的形式,参数是HTTP请求头部
cookies:字典或cookieJar,Request中的cookie
json:JSON格式的数据,作为equests的内容
data:字典、字节系列或文件对象,作为requests的内容
3.Requests库的get方法
#这是一个get请求的方法,传入url,及params参数
response = requests.get(url,params=params)
#获取响应的内容 result = response.content.decode()
#将json格式转换为python对象 json_obj = json.loads(result)
这段代码的解释:
这段代码是使用Python的requests库来发送一个GET请求到指定的URL,然后解码并获取响应的内容。
url是网站的Request URL,params是查询参数(通常用于在URL中传递数据)。
response.content返回的是一个字节字符串,因此需要使用decode()方法将其转换为正常的字符串。这里decode()括号内默认的是UTF-8编码,如果不适配我们也可以选择换别的编码如GBK,ASCLL等
json.loads() 是 Python 的 json 模块中的一个函数,用于将 JSON 格式的字符串转换为 Python 对象。
在你给出的代码中,result 是一个包含了 JSON 数据的字符串。通过调用 json.loads(result),这个字符串被解析成了 Python 的数据结构,比如字典、列表等。例如,如果 result 是这样的 JSON 字符串:'{"name": "John", "age": 30}',那么 json.loads(result) 的结果将是一个字典:{'name': 'John', 'age': 30}。
注意:如果 result 不是一个有效的 JSON 字符串,json.loads() 会抛出一个 json.decoder.JSONDecodeError 错误。所以在调用 json.loads() 时,最好使用 try/except 来捕获可能出现的错误。
三:当网站的数据是一个HTML格式的时候我们就要用到另外一种库lxml与xpath
lxml 是一种解析xml/html的类库,可以通过一些表达式,自由取出节点的属性以及内部值
xpath 一种路径表达式,一定的规则在xml/html中取数据
1.安装路径:pip install lxml
2.用lxml解析网站
#这是一个get请求的方法,传入url,及params参数 response = requests.get(url,params=params) #获取响应的内容 result = response.content.decode() #将解码后的字符串解析为一个HTML树的表示 root = etree.HTML(result)
与上方相同的代码只是解析的方法不同etree.HTML(result): 这行代码使用lxml库的etree.HTML()函数将解码后的字符串解析为一个HTML树的表示。这个函数返回一个Element对象,表示HTML文档的根元素。
通过这三行代码,你可以获取并解析HTML页面,以便提取页面中的信息或进行其他操作。
3.xpath的路径表达式
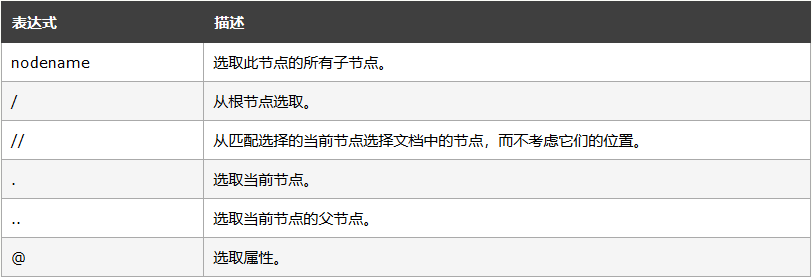
补充:text() 选取内部文本值 innerHTML
四:基础的防反爬手段
当我们访问一些存在反爬的网站时可以用一些简单的方法来跳过
1.添加请求头,在一些网站中我们需要添加请求头来合理我们的请求身份,基于此我们可以添加一些请求头
2.添加cookie值,添加浏览器的储存数据来达到访问条件
3.更换ip,当我们访问的频率过高时一些网站会禁用此ip这个时候我们可以选择更换请求IP来实现访问
五:爬虫的Robots协议
1.什么时Robots协议
Robots协议是一种网络爬虫排除标准,用于规定搜索引擎爬虫如何访问网页,以及哪些网页可以被爬取。该协议通常存储在网站根目录下的robots.txt文件中。
Robots协议可以由网站所有者创建并更新,以告诉搜索引擎爬虫哪些页面可以访问,哪些页面不能访问。其中,User-agent和Disallow是最常见的两个指令。User-agent用于指定哪些爬虫需要遵守该协议,Disallow则用于告诉爬虫哪些URL不能被访问。
需要注意的是,虽然Robots协议是一种建议性的标准,而非强制性的法律文件,但在许多情况下,遵守该协议可以避免网站受到恶意攻击或数据泄露等风险。因此,在进行网络爬虫开发和使用时,一定要遵守Robots协议。
2.查看Robots协议
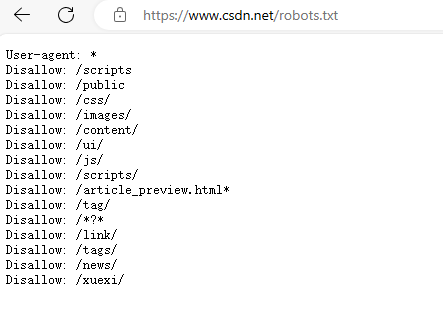
在目标网站后面加上/robots.txt,例如访问https://www.csdn.net/robots.txt
*代表所以,/表示根目录
User-agent: *表示该规则对所有的搜索引擎有效。Disallow: /表示禁止爬取根目录下的所有网页,而Allow: /则表示允许爬取根目录下的所有网页。
因为网络爬虫过于频繁会给网站服务器带来巨大的额外资源开销以及存在泄露数据的风险等所有我们在爬取数据时一定要注意
对于Robots协议:
访问量小,小网站及非商业的网站可以遵守
访问量大,商业盈利的网站建议必须遵守