python必坑知识点01
一、基础:
1、%占位符的使用
print('%s, 下载90%s了' % ('兄弟', '%'))
print('%s, 下载90%%了' % '兄弟') # 双%
2、填充0
#''.zfill()
print('alex'.zfill(10))
3、逻辑运算
v2 = "wupeiqi" and "alex"
# 第一步:将and前后的只转换为布尔值 True and True
# 第二步:判断本次操作取悦于谁?由于前面的是True,所以本次逻辑判断取决于后面的值。
# 所以,后面的只等于多少最终结果就是多少。 v2 = "alex"
二、列表循环删除
# 错误方式, 有坑,结果不是你想要的。
user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"]
for item in user_list:
if item.startswith("刘"):
user_list.remove(item)
print(user_list)
# 正确方式,倒着删除。
user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"]
for index in range(len(user_list) - 1, -1, -1):
item = user_list[index]
if item.startswith("刘"):
user_list.remove(item)
print(user_list)
三、元组定理
如何体现不可变呢?
记住一句话:《"我儿子永远不能换成是别人,但我儿子可以长大"》
# 面试题
比较值 v1 = (1) 和 v2 = 1 和 v3 = (1,) 有什么区别?
"""
v1=v2是整形,v3是元组
"""
四、集合
1、存储原理

2、元素必须可哈希
# list、set是不可哈希的
v1 = [11,22,["alex","eric"],33]
v2 = set(v1) # 报错
print(v2)
# 集合的查找效率非常高(数据量大了才明显)
# 定义空 set()
# 由于True和False本质上存储的是 1 和 0 ,而集合又不允许重复,所以在整数 0、1和False、True出现在集合中会有如下现象
v1 = {True, 1}
print(v1) # {True}
五、字典
在Python2中 字典.keys()、.values()、.items()直接获取到的是列表,而Python3中返回的是高仿列表,这个高仿的列表可以被循环显示
六、浮点型
坑(所有语言中)可以自行百度理解一下
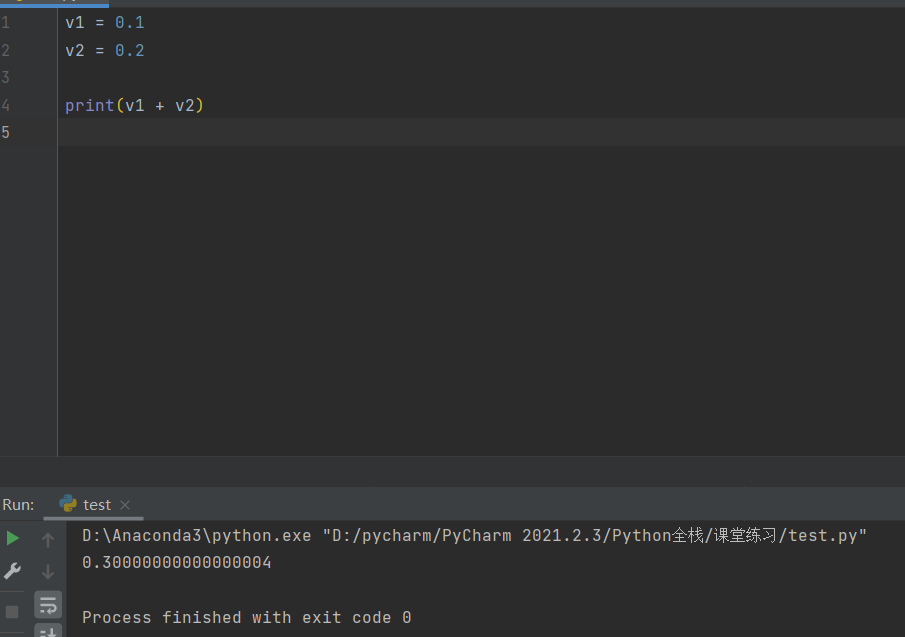
精确小数
# 在项目中使用精确的小数计算
import decimal
v1 = decimal.Decimal("0.1")
v2 = decimal.Decimal("0.2")
v3 = v1 + v2
print(v3) # 0.3
七、注释
# 分阶段实现的后续功能用todo注释

八、位运算
计算机底层本质上都是二进制,我们平时在计算机中做的很多操作底层都会转换为二进制的操作,位运算就是对二进制的操作。
-
&,与(都为1即为1)
a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a & b # 12 = 0000 1100 -
|,或(只要有一个为1)
a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a | b # 61 = 0011 1101 -
^,异或(值不同)
a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = a ^ b # 49 = 0011 0001 -
~,取反
a = 60 # 60 = 0011 1100 c = ~a; # -61 = 1100 0011 -
<<,左移动
a = 60 # 60 = 0011 1100 c = a << 2; # 240 = 1111 0000 -
>>,右移动
a = 60 # 60 = 0011 1101 c = a >> 2; # 15 = 0000 1111
平时在开发中,二进制的位运算几乎很好少使用,在计算机底层 或 网络协议底层用的会比较多,例如:
-
计算 2**n
2**0 1 << 0 1 1 2**1 1 << 1 10 2 2**2 1 << 2 100 4 2**3 1 << 3 1000 8 ... -
计算一个数的一半【面试题】
v1 = 10 >> 1 print(v1) # 值为5 v2 = 20 >> 1 print(v2) # 值为 10 -
网络传输数据,文件太大还未传完(websocket源码为例)。
第1个字节 第2个字节 ... 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-------+-+-------------+-------------------------------+ |F|R|R|R| opcode|M| Payload len | Extended payload length | |I|S|S|S| (4) |A| (7) | (16/64) | |N|V|V|V| |S| | (if payload len==126/127) | | |1|2|3| |K| | | +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - + FIN位置是0,表示这是一部分数据,后续还有数据。 FIN位置是1,表示这是最后数据,已发送完毕。
九、考核
# 简述你理解的 ascii、unicode、utf-8、gbk 编码
ascii编码、unicode字符集、utf-8编码、gbk编码本质上都是字符与二进制的关系。
- ascii,只有256种对照关系,只包含英文、符号等。
- unicode,万国码,包含了全球所有文字和二进制之间的一个对应关系。(ucs2或ucs4)
- utf-8,对unicode字符集的码位进行压缩处理,间接也维护了字符和二进制的对照表。
- gbk,包含中国、日本韩国等亚洲国家的文字和二进制的对照表。
# py2和py3默认解释器编码分别是什么?如何在代码中修改解释器的编码?
py2:ascii
py3:utf-8
在文件的顶部加一句: # -*- coding:编码 -*-
# 列举你了解的Python2和Python3的区别
- 默认解释器编码 ascii utf-8
- 整型和长整形
- 地板除取整、取小数
- 字典的keys()/values()/items() 获取的值不同。
- py2,字典无序;py3.6+ 字典有序。
# 可哈希和不可哈希类型
1.哈希类型,即在原地不能改变的变量类型,不可变类型。
数字类型,字符串,元组,布尔,冻结集合(frozensetbu'ke),None
2.原地可变类型:list、dict和set。它们不可以作为字典的key,也不可以嵌套在集合中。
set是ke'bi