SQL 基础语法 增删查改 连接
一、基本操作
1、创建数据库
create database '名字'
2、创建表
CREATE TABLE Persons
(
PersonID int primary key(主键) identity(1,1) (标识列),
LastName varchar(255) Unique(唯一约束),
Sex char(2) check(Sex='男'orSex='女'),
Address varchar(255),
City varchar(255)
);3、修改基本表
ALTER TABLE table_name
ADD column_name datatype --添加
DROP COLUMN column_name --删除
ALTER COLUMN column_name datatype --修改4、插入数据 有逗号!
INSERT
INTO Websites (name, url, country)
VALUES ('stackoverflow', 'http://stackoverflow.com/', 'IND'),
('stackoverflow', 'http://stackoverflow.com/', 'IND');5、修改数据
UPDATE Person
SET FirstName = 'Fred',Sex='男'
WHERE LastName = 'Wilson' 6、删除数据
DELETE
FROM Person
WHERE LastName = 'Wilson' 二、数据查询!
1、单表查询
SELECT * FROM Persons
SELECT LastName,FirstName FROM Persons2、Where 条件查询
1.
SELECT distinct FirstName FROM Personsdistinct 消除取值重复行
2.
SELECT * FROM Persons WHERE Year>1965
SELECT LastName,FirstName FROM Persons
WHERE Sage Not BETWEEN 20 AND 23 S<20 S>23 BETWEEN包含边界select * from hs_user where ID like '%123%'
%:表示任意0个或多个字符。可匹配任意类型和长度的字符
_: 表示任意单个字符。匹配单个任意字符,
[ ]:表示括号内所列字符中的一个(类似正则表达式)
[^ ] :表示不在括号所列之内的单个字符3.
select * from Persons where PaperType is null is null判断为空3、聚合函数 查询
select count(*) 返回某列的行数 count()为空时返回结果为0
select count(distinct Persons) (计算非重复结果的数目)
select max(StudentID)
select min(StudentID)
select SUM(IsUse) 返回数值列的总数(总额) sum()为空时返回结果为null
select avg(StudentID) 平均4、order by 排序
select CollegeID
from Persons
order by CollegeID desc 默认asc升序 desc降序5、group by 分组
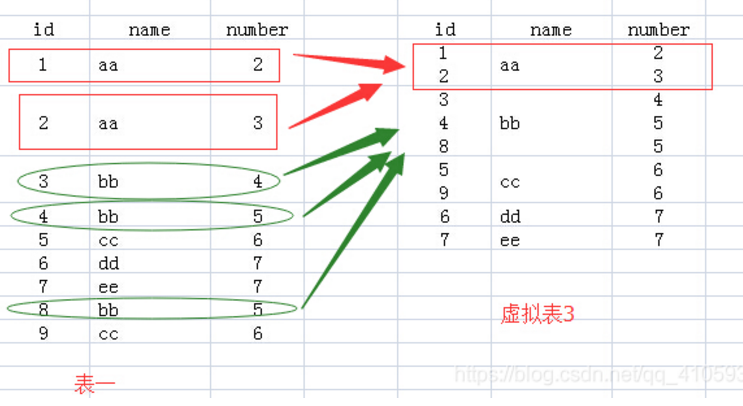
select name,sum(number) from test group by name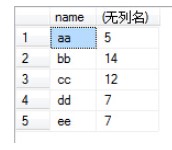
注意:having 是针对分组的条件选择
select 类别, sum(数量) as 数量之和 from A
group by 类别
having sum(数量) > 186、查重!!
--查询重复字段次数
SELECT 字段, COUNT ( * )
FROM 表
GROUP BY 字段
HAVING COUNT ( * ) > 1--查询重复数据全部
SELECT 字段,a.*
from 表 a
WHERE 字段 in(Select 字段 From 表 Group By 字段 Having Count(*) > 1 )
order by a.字段 三、连接查询
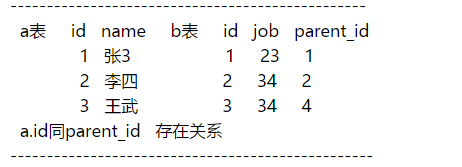
1.内连接 (左右未对应的 不显示)
select a.*,b.*
from a inner join b on a.id=b.parent_id 结果是
1 张3 1 23 1
2 李四 2 34 2
1 张3 1 23 1
2 李四 2 34 2
2.左连接 (右未对应的 显示null)
select a.*,b.*
from a left join b on a.id=b.parent_id 结果是
1 张3 1 23 1
2 李四 2 34 2
3 王武 null
1 张3 1 23 1
2 李四 2 34 2
3 王武 null
3.右连接 (左未对应的 显示null)
select a.*,b.*
from a right join b on a.id=b.parent_id 结果是
1 张3 1 23 1
2 李四 2 34 2
null 3 34 4
1 张3 1 23 1
2 李四 2 34 2
null 3 34 4
四、其他
1、ISNULL 判断是否为空
isnull(value1,value2)
1、value1与value2的数据类型必须一致。
2、如果value1的值不为null,结果返回value1。
3、如果value1为null,结果返回vaule2的值。vaule2是你设定的值(null)。
2、offset (查询页码-1)*每页条数 rows fetch next 每页条数 rows only 分页
关键字解析:
- Offset子句:用于指定跳过(Skip)的数据行; //(页码-1)*每页条数=之前所有数据
- Fetch子句:该子句在Offset子句之后执行,表示在跳过(Sikp)指定数量的数据行之后,返回一定数据量的数据行;
- 执行顺序:Offset子句必须在Order By 子句之后执行,Fetch子句必须在Offset子句之后执行;
分页实现的思路:
- 在分页实现中,使用Order By子句,按照指定的columns对结果集进行排序;
- 使用Offset子句跳过前N页:Offset (@PageIndex-1)*@RowsPerPage rows;
- 使用Fetch子句呈现当前Page:Fetch next @RowsPerPage rows only;
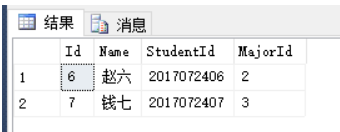
列如:
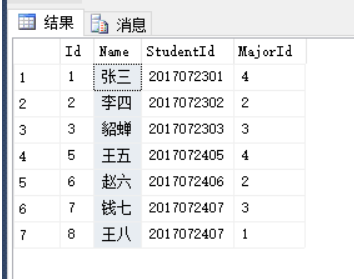
select [Id],[Name],[StudentId],[MajorId]
from T_Student
order by [Id]
offset (3-1)*2 rows
fetch next 2 rows only结果如下:
五、执行顺序
1、from 子句组装来自不同数据源的数据; (1) FROM <left_table> (2) <join_type> JOIN <right_table> (3) ON <join_condition>
2、where 子句基于指定的条件对记录行进行筛选; (4) WHERE <where_condition>
3、group by 子句将数据划分为多个分组; (5) GROUP BY <group_by_list>
4、使用聚集函数进行计算; (6) WITH {CUBE | ROLLUP}
5、使用 having 子句筛选分组; (7) HAVING <having_condition>
6、计算所有的表达式;
7、select 的字段; (8) SELECT (9) DISTINCT
8、使用 order by 对结果集进行排序。 (9) ORDER BY <order_by_list> (10) <TOP_specification> <select_list>